


10 let od liberalizace Internetu v ČR: Jak se kdysi hledalo?
Najít dnes něco na Internetu je relativně snadné. Stačí jít na stránky nějakého fulltextového vyhledávače a zde popsat to, co hledáte. Ostatní už je pak hlavně otázka toho, jak dobře či špatně jste se zeptali. Před deseti lety to ale takto jednoduché rozhodně nebylo. Tehdy žádný Gogole neexistoval, a ísto něj zde byla řada specifických služeb pro různé druhy hledání.Když se před deseti lety (v roce 1995) liberalizoval český Internet, již na něm existovala řada vyhledávacích služeb, pro hledání všeho možného. Oproti dnešním "univerzálním" vyhledávačům, jako je např. Google, samozřejmě nebyly zdaleka tak mocné a s tak širokým záběrem. Lišily se ale i v jedné další podstatné věci: byly to samostatné služby. Dnešní vyhledávače typu Google jsou realizovány jako nadstavba nad platformou webu, a uživatel si pro ně nemusí instalovat žádného specifického klienta a učit se s ním pracovat. Pouze navštíví (nechá si zobrazit) příslušné WWW stránky, načež se mu objeví vyhledávací formulář, do něj zadá to co hledá, a výsledek dostane opět ve formě WWW stránky.
Před deseti lety tomu tak obvykle nebylo. Vyhledávací služby byly jednak úzce specializované, například na vyhledávání souborů, na prohledávání textů nějakých dokumentů, či třeba nahledání lidí. Hlavně to ale byly samostatné služby, s vlastními protokoly, s vlastními klienty i servery, i vlastním stylem a způsobem práce, který se uživatel musel naučit, pokud chtěl s příslušnou službou pracovat. Lidé pak měli na svém počítači instalovány celou řadu různých klientů, a s každým z nich se museli učit pracovat samostatně. Oproti tomu je dnešní stav, s jediným browserem a jediným stylem práce (vyplňováním formulářů) opravdu "o něčem jiném".
Pak zde byl ale ještě jeden rozdíl oproti dnešnímu stavu, a to také hodně významný. Uživatel, který něco hledal, se nemohl zeptat "na jediném místě", resp. "do éteru", s tím že vyhledávací služba už si s tím nějak poradí a sama najde toho, kdo zná odpověď a tu poskytne. Dnes třeba zadáte službě Google určité klíčové slovo a očekáváte, že vám najde všechny texty (webové stránky, dokumenty, ale třeba také soubory atd.), ve kterých se zadané slovo vyskytuje. Už jí neříkáte nic o tom, kde má tyto dokumenty hledat, resp. které dokumenty má prohledávat. Ona prostě prohledá všechna místa, o kterých ví že existují (které má tzv. zaindexovány).
Před deseti lety tomu ale bylo jinak, a většina vyhledávacích služeb fungovala na jiném principu: existoval určitý počet serverů příslušné služby, a každý z nich obvykle "věděl" jen o něčem. Třeba služba WAIS pro plnotextové vyhledávání používala řadu vyhledávacích serverů, z nichž každý měl "pod sebou" jednu databázi dokumentů a vyhledával pouze v ní. Uživatel, který něco konkrétního hledal, pak musel nejenom zadat to co hledá, ale musel také vybrat konkrétní WAIS servery (vlastně: databáze dokumentů), které měly být podle jeho dotazu prohledány.
Takže nalezení něčeho konkrétního bylo podstatně větší alchymií než dnes.
Archie
Služba Archie, jak už její název naznačuje, sloužila k vyhledávání v archivech souborů. Tedy v FTP archivech, protože právě tento protokol FTP, File Transfer Protocol) je v Internetu využíván pro práci s archivy souborů.
Princip fungování této služby byl vcelku přímočarý a jednouchý: každý Archie server vždy "věděl" o určitém počtu FTP serverů (které se mu samy přihlásily či se o nich dozvěděl nějak jinak). Tyto servery pravidelně obcházel, nechával si vypisovat všechny soubory, které tyto FTP archivy obsahovaly, a výsledek si pamatoval. Když se pak takovéhoto Archie serveru někdo zeptal na nějaký konkrétní soubor, on tyto své "výpisy" prohledal, a pokud hledaný soubor nalezl, poskytl tazateli informaci ve smyslu: hledaný soubor najdeš tam a tam (na takovém a takovém uzlu, v takovém a takovém adresáři). Bylo pak na uživateli, aby se na k příslušnému FTP archivu připojil a požadovaný soubor si stáhnul (pomocí služby FTP).
Vlastní vyhledávání tedy bylo odděleno od následného "stahování". V lepším případě však byly obě etapy vzájemně povázány: výsledek vyhledání službou Archie mohl mít formu hypertextového odkazu, na který stačilo kliknout, a tím se aktivoval příslušný FTP klient, který již zařídil vše potřebné.
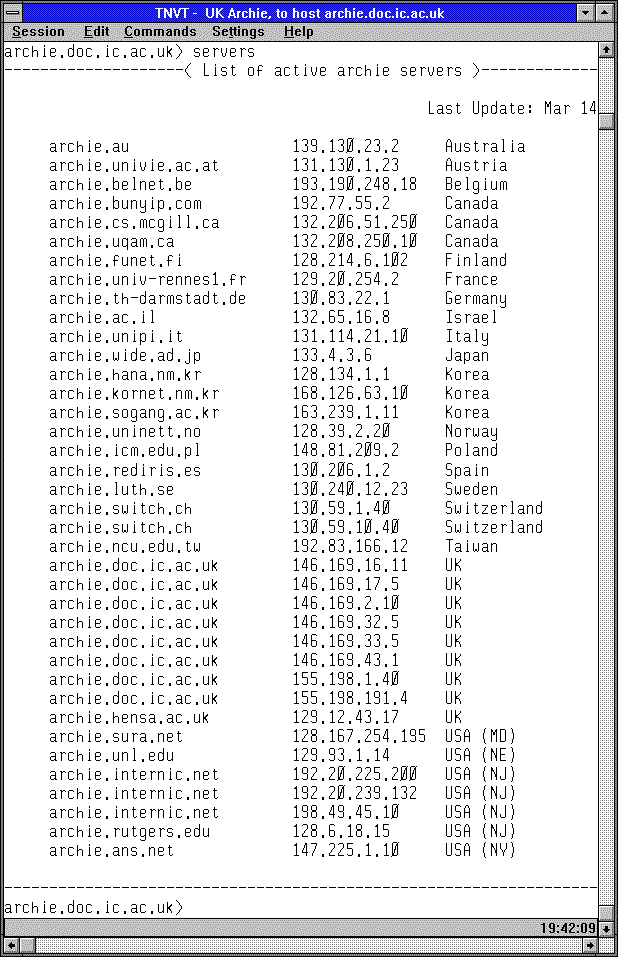
V praxi tedy existovala celá řada Archie serverů, kterých se uživatelé mohli ptát (a často dostávali dosti odlišné výsledky). Způsobů, jakým se dalo ptát Archie serverů, bylo přitom více. Jednou z možností bylo vzdálené přihlášení, prostřednictvím Telnetu. Pak vlastně uživatel přímo komunikoval s klientským rozhraním, běžícím přímo na příslušném Archie serveru. Mělo to ale tu nevýhodu, že když se požadovaný soubor nenašel, musel uživatel sám "přejít" k jinému serveru a zde pokračovat v hledání. Naštěstí jednotlivé Archie servery o sobě většinou věděly navzájem a dokázaly uživateli vypsat příslušný seznam svých "kolegů".
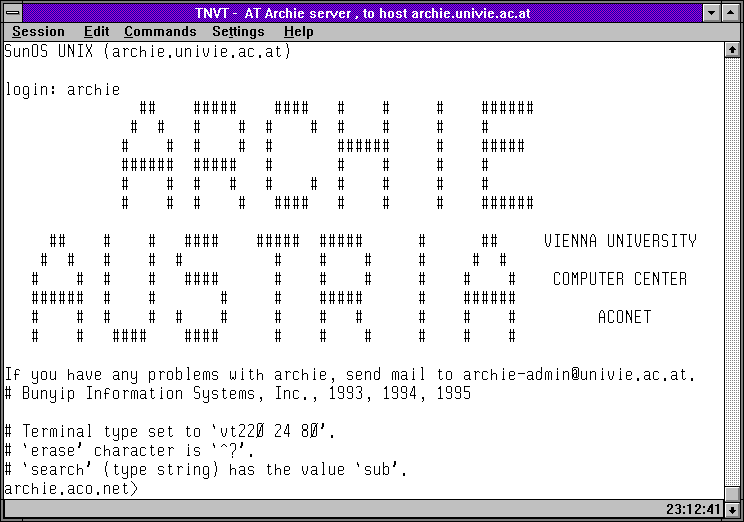
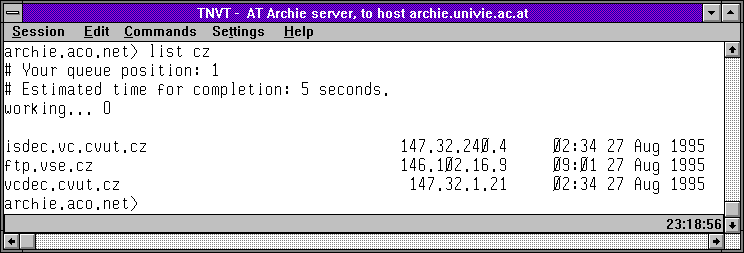
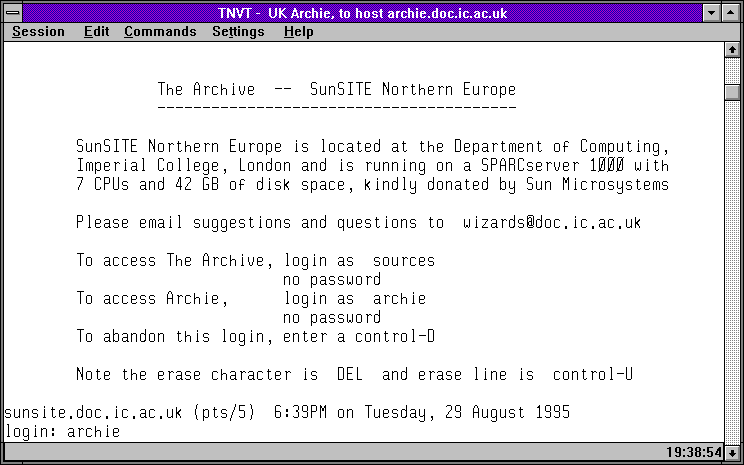
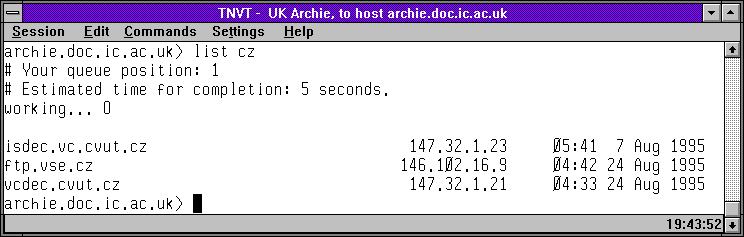
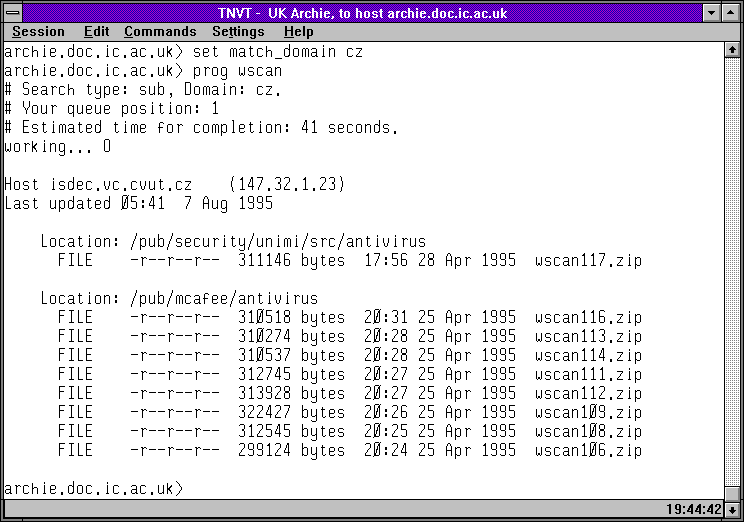
Následující skupina obrázků ukazuje právě tento způsob práce se servery Archie (skrze Telnet). Na prvních obrázku je úvodní obrazovka rakouského Archie serveru, a na druhém výpis toho, které české FTP archivy (resp.: v doméně .cz) prohledává. Třetí a čtvrtý obrázek ukazuje to samé pro britský Archie server. Konečně pátý obrázek ukazuje seznam Archie serverů, vypsaný britským serverem, a poslední šestý obrázek ukazuje výsledek vyhledání souborů s konkrétním jménem (obsahujících řetězec wscan), s odkazy na umístění nalezených souborů na českých FTP archivech.
 |  |
 |  |
 |  |
Na následujících dvou obrázcích vidíte příklad použití lokálních Archie klientů. Tedy programů běžících přímo u uživatele, které se jej vyptají na dvě základní informace:
- co chce hledat (jméno souboru, resp. nějaký podřetězec)
- kde to chce hledat (na kterém Archie serveru).
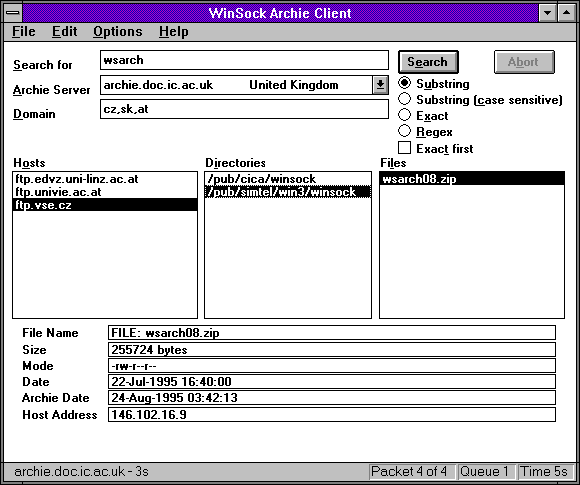 | 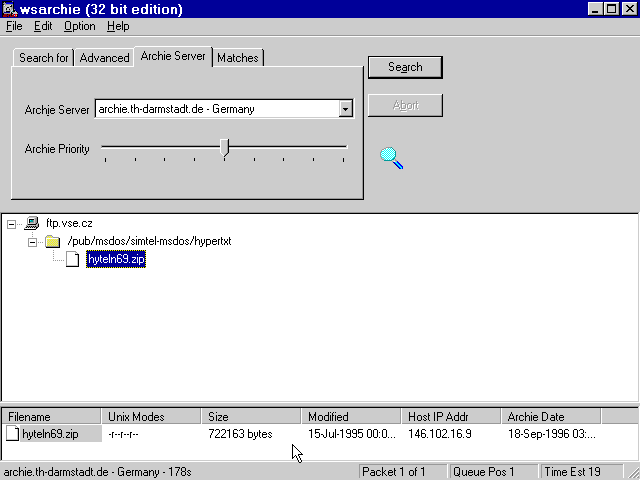 |
Výsledkem vyhledání je pak odkaz na konkrétní umístění hledaného souboru. Postup hledání je tedy v zásadě stejný jako u vzdáleného přístupu k serverům Archie přes Telnet
Časem, díky rozvoji služby WWW, se objevilo také WWW rozhraní ke službě Archie. Jmenovalo se "ArchiePlex", a již dokázalo oslovit více Archie serverů najednou (přesněji ty, které si uživatel sám vybral a označil). Uživatel měl k dispozici WWW stránku, do které vepsal jméno hledaného souboru. Výsledek pak dostal také ve formě WWW stránky, s odkazem na umístění hledaného souboru (viz následující dva obrázky)
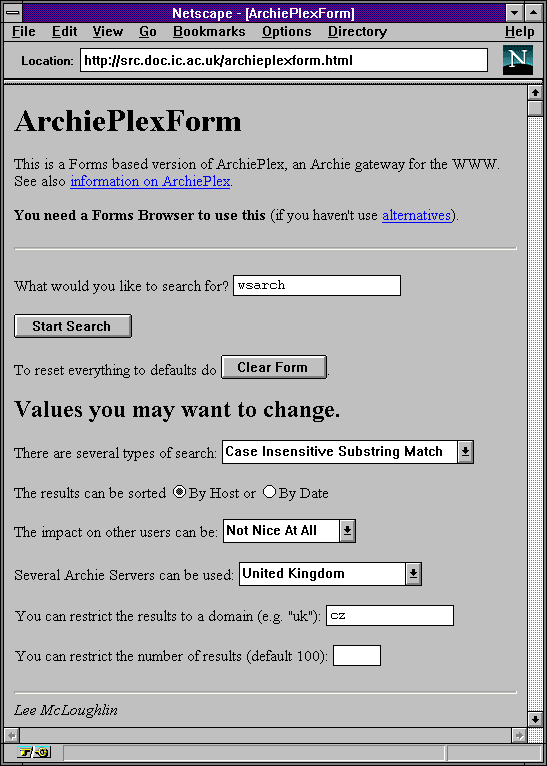 | 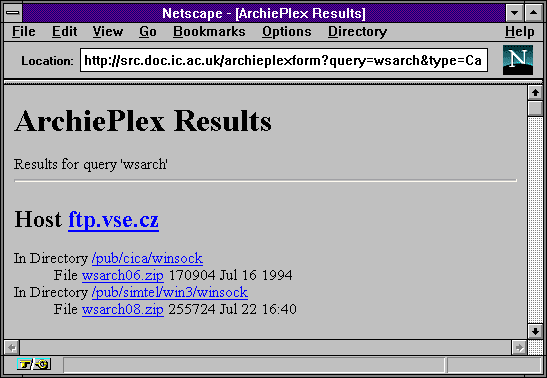 |
Živou ukázku práce s lokálním klientem služby Archie si můžete prohlédnout zde. Podrobněji se o této službě můžete dočíst zde a zde.
Nosey Parker
Služba Archie byla svého času velmi populární a používaná. Zajímavé ale je, že do ČR se nikdy nedostala - ani v době její největší slávy u nás nebyl žádný server této služby. Proč?
Důvod je jednoduchý: příslušný server stál dost peněz, a ty tehdy nebyly k dispozici. A tak došlo na jiné řešení: v Liberci, na tamní Technické univerzitě, vyvinuli vlastní řešení pro prohledávání FTP archivů a vyhledávání souborů. Výsledná služba se jmenoval Nosey Parker, v češtině pak "Čmuchal". Podle stále neověřených zpráv to prý nesouvisí ani tak se způsobem vyhledávání souborů, jako spíše s velikostí nosu autora, pan Jiřího Randuse (viz obrázek).
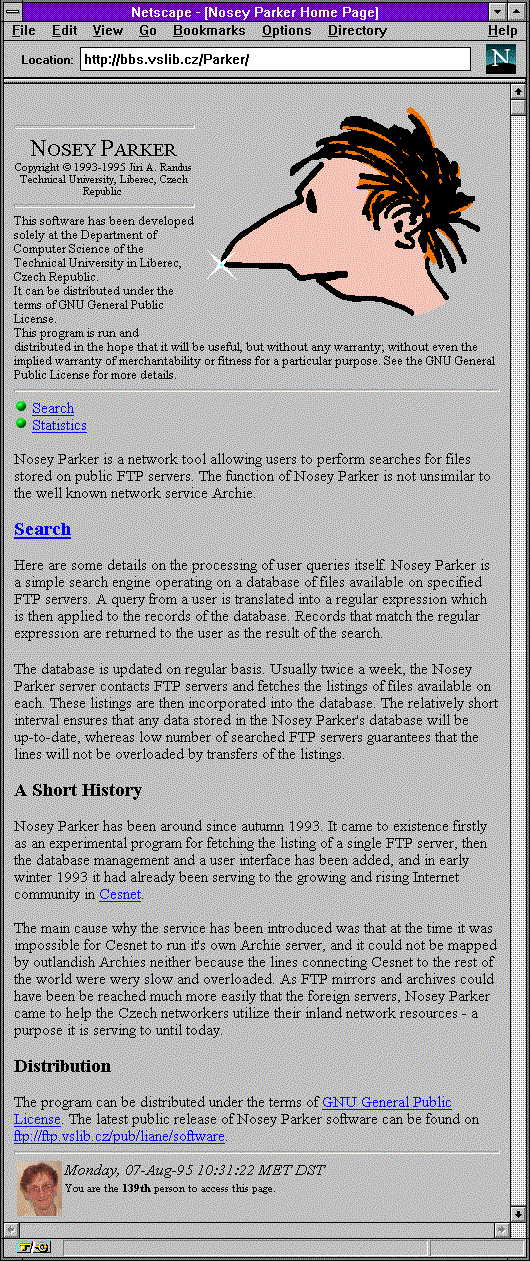 | 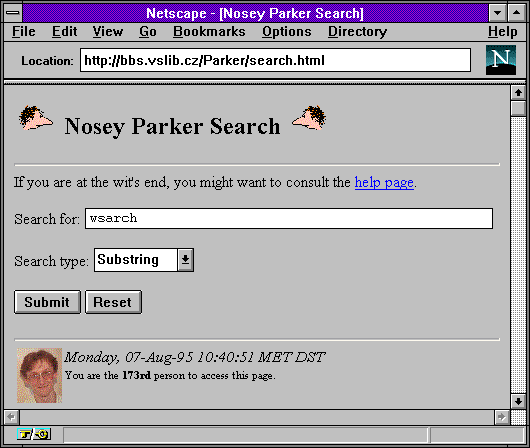 | 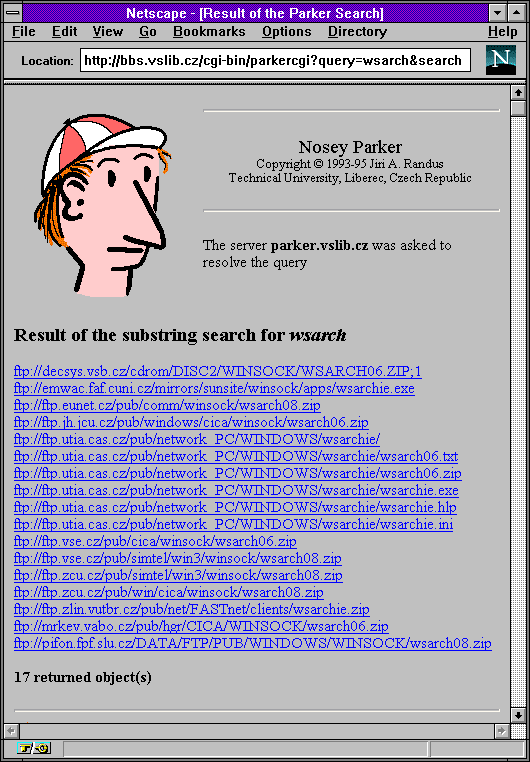 |
Zajímavé bylo také to, že tato služba vznikla již jen jako nadstavba nad WWW, a neměla nikdy žádného svého klienta. V tomto ohledu tedy byla oproti původnímu Archiemu modernější. Kromě toho bylo možné se k Čmuchalovi (službě Nosey Parker) dostat i přes email, Gopher nebo Telnet. To ukazují následující obrázky
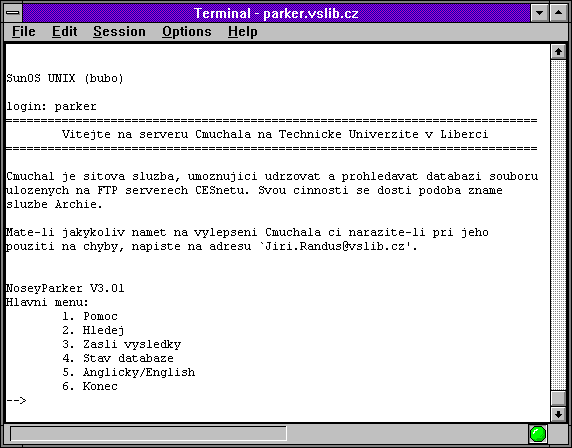 | 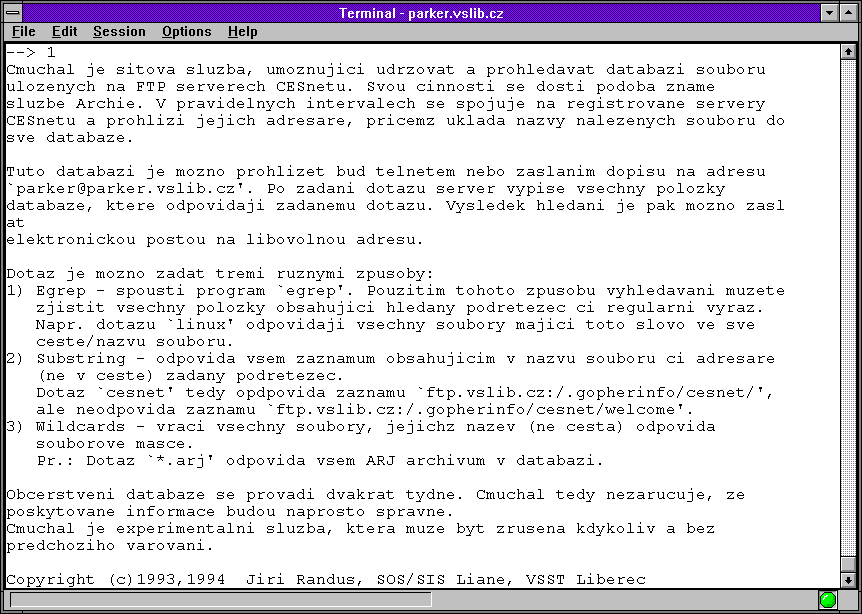 | 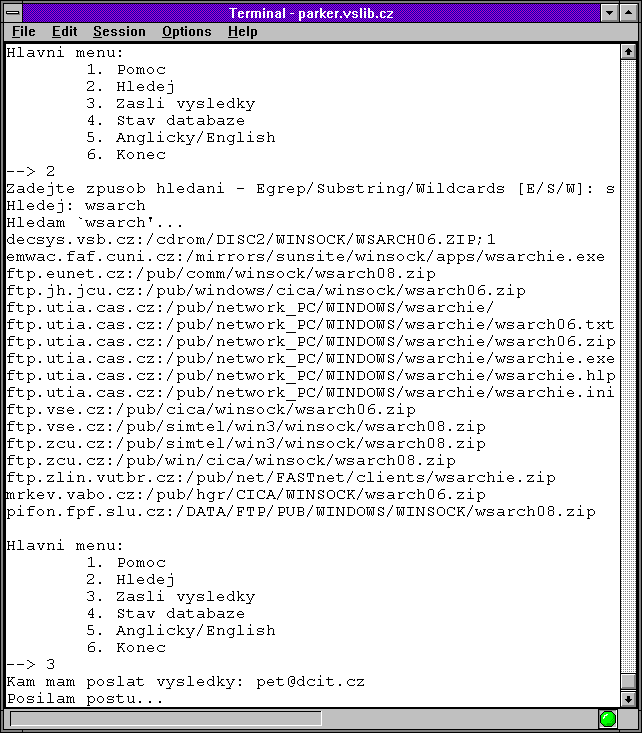 |
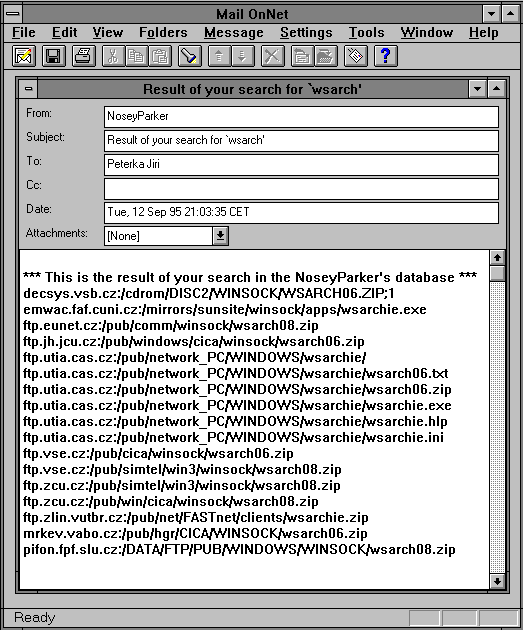 | 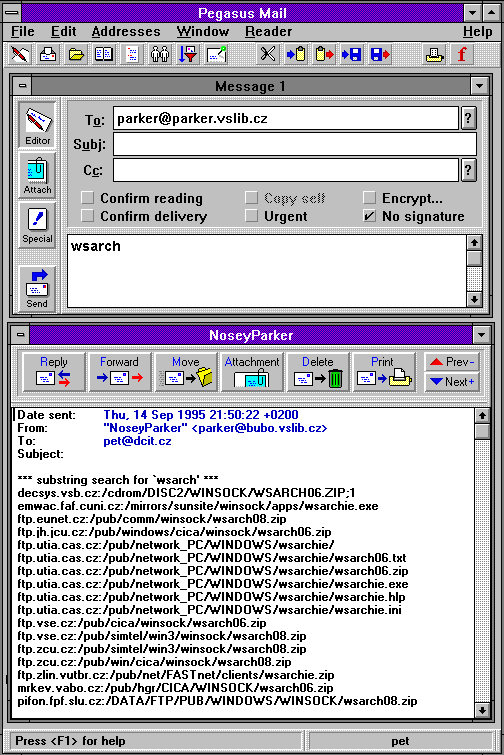 | 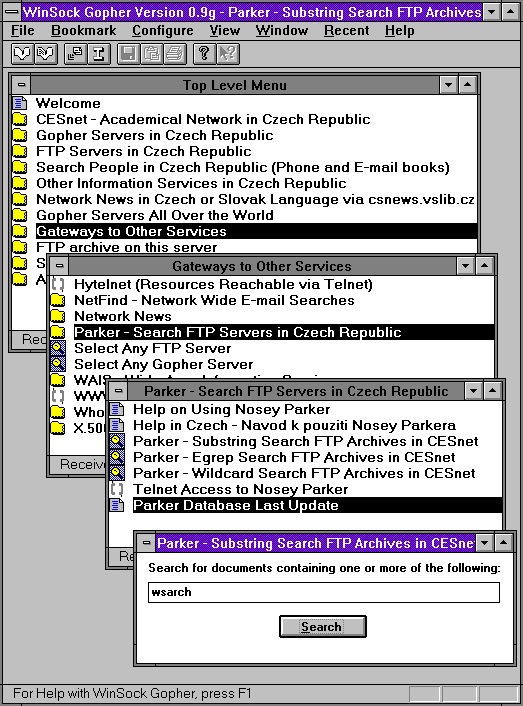 | 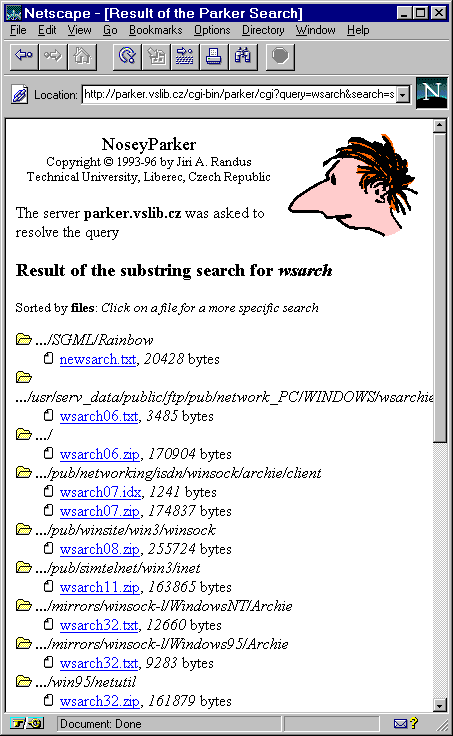 |
Podrobněji se o této službě můžete dočíst zde, a živou ukázku práce s dnes již nedostupnou službou můžete shlédnout zde.
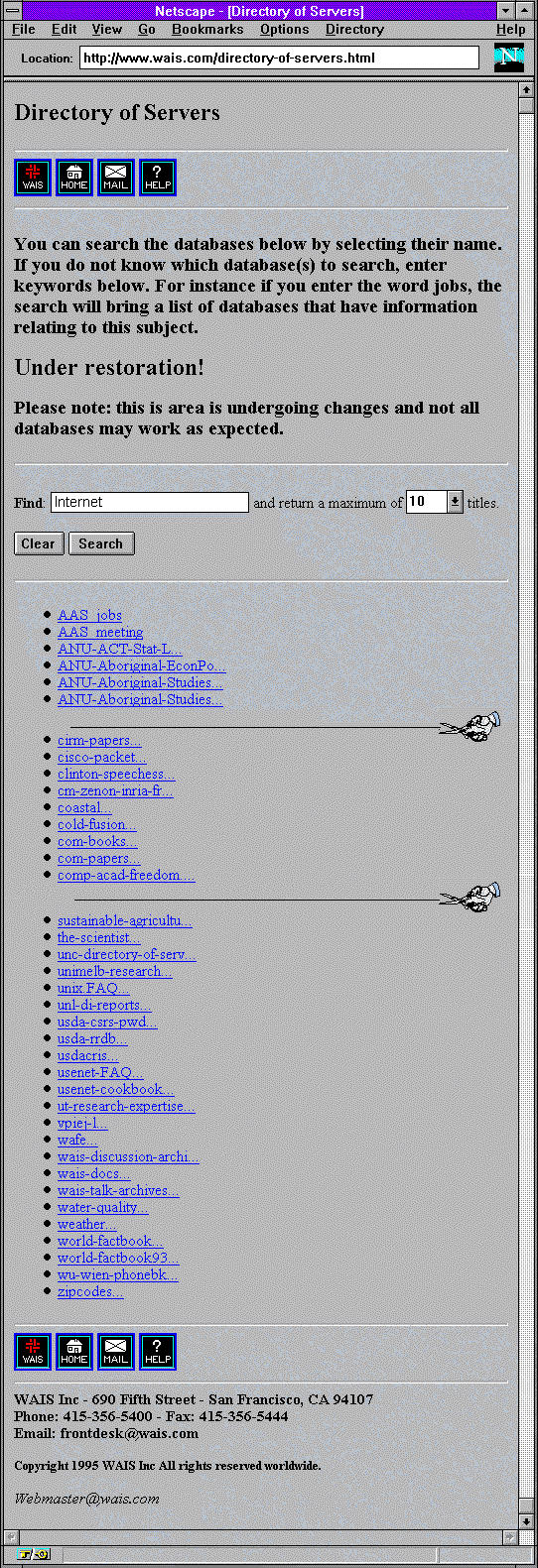
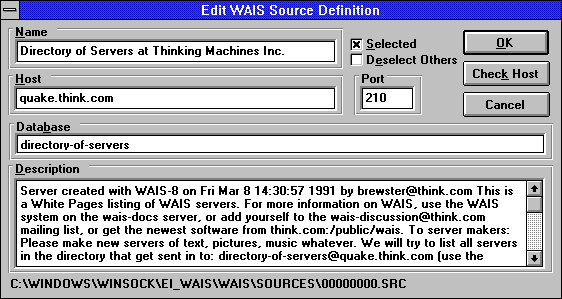
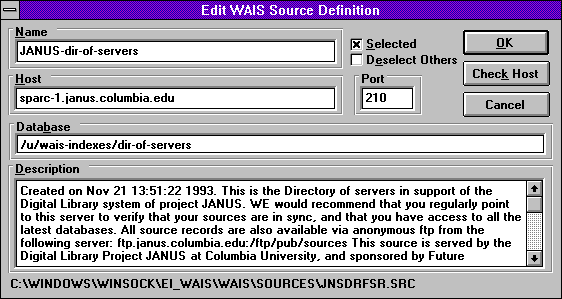
WAIS
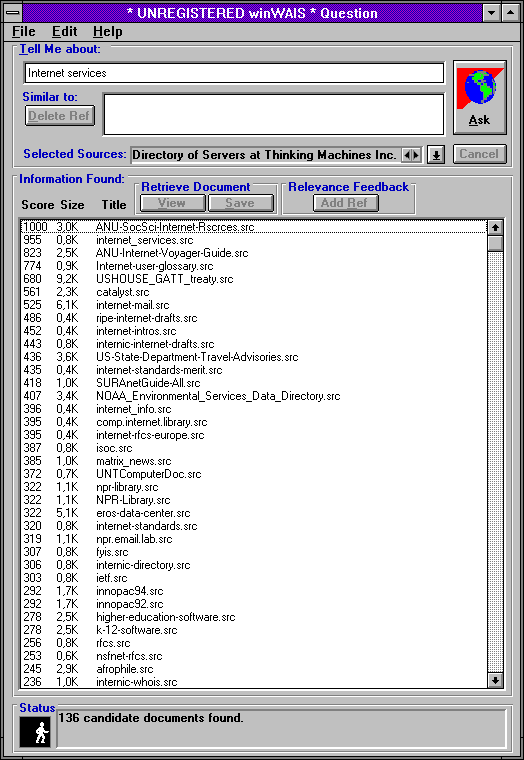
Třetí vyhledávací služba, o které si dnes řekneme, je asi tím hlavním předchůdcem dnešních plnotextových vyhledávačů. Jde o službu WAIS ( Wide Area Information Service). Nabízela sice plnotextové vyhledávání, ale ne "kdekoli", jako dnešní vyhledávače. Místo toho existovaly jednotlivé servery této služby, a každý z nich měl vždy "pod sebou" určitou databázi textových dokumentů. No a možnost plnotextového vyhledávání nabízel pouze v této jedné databázi. Jak jsme si již uvedli na začátku, uživatel se musel nejen správně zeptat (formulovat svůj dotaz), ale musel si také umět vybrat ten správný server služby WAIS, kterého se zeptat.
Následující obrázky ukazují způsob práce se službou WAIS prostřednictvím lokálního klienta. Ten umožňuje nejprve vybrat více WAIS serverů, kterým pak předá uživatelův vyhledávací dotaz.
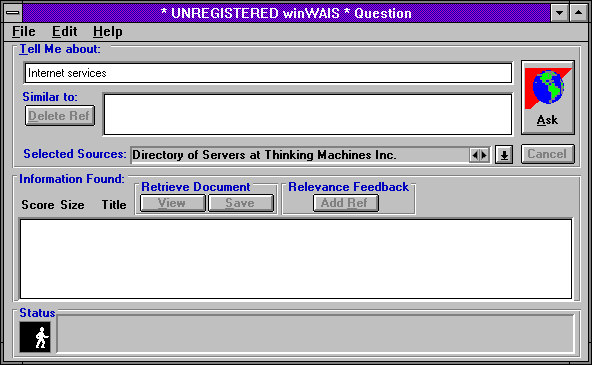 | 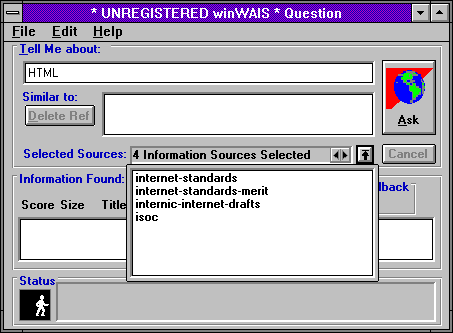 |  |
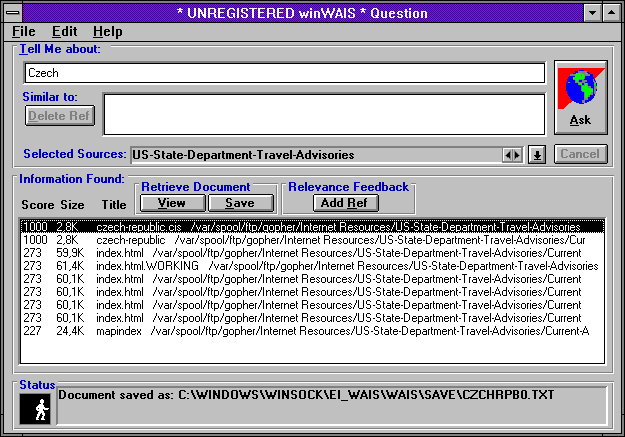 | 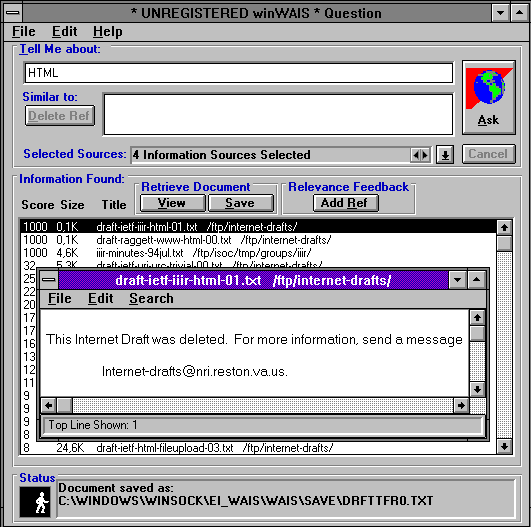 | 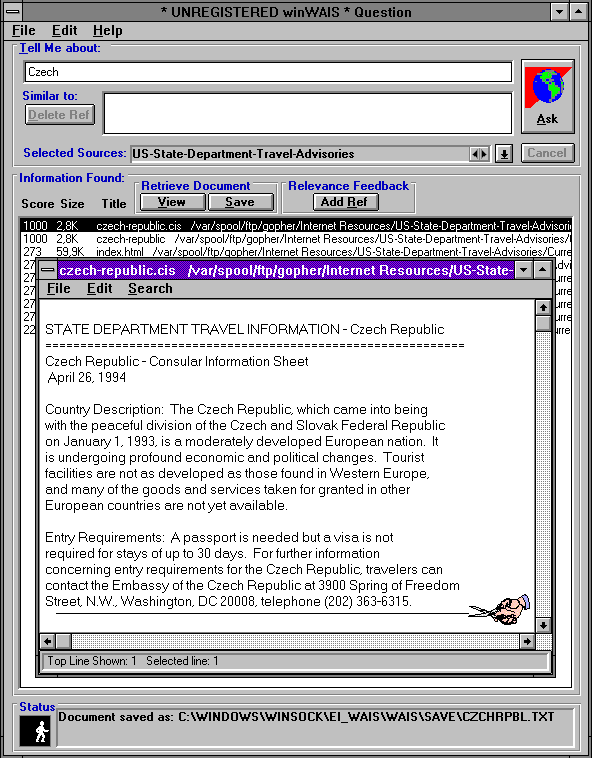 |
Vedle toho však ke službě WAIS existovalo i WWW rozhraní. Některé servery WAIS měly své vlastní webové rozhraní, skrze které bylo možné hledat pouze v "jeho" dokumentech. Jiné servery pak "rozdělovaly" dotazy mezi více WAIS serverů, sbíraly jejich odpovědi a prezentovaly je uživateli najednou.
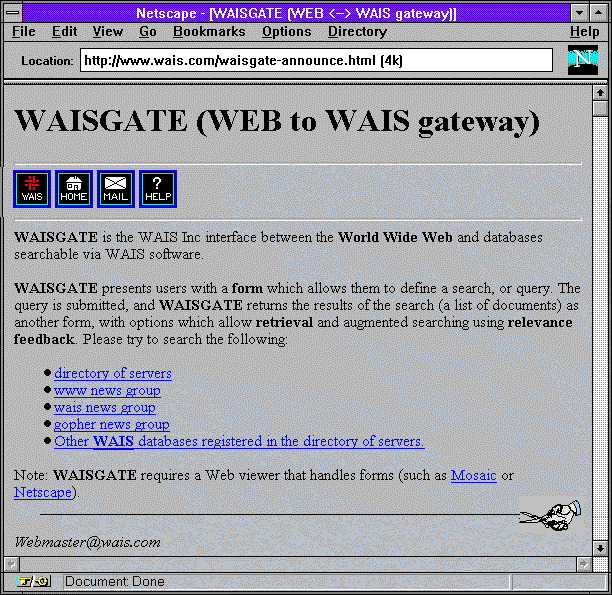 | 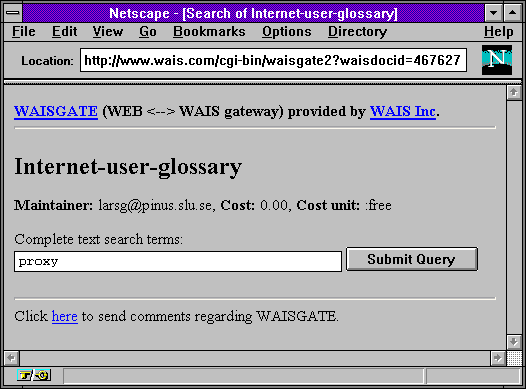 |  |
Existovaly však ještě další možnosti, jak přistupovat ke službě WAIS a vyhledávat v ní. Mimo jiné i skrze Telnet, jak ukazují následující obrázky.
 |  |  |
V každém případě ale byly možnosti a komfort vyhledávání u služby WAIS zcela nesrovnatelné s tím, co dnes nabízí moderní vyhledávače, stojící na platformě webu. Takže vlastně ani není moc škoda, že služba WAIS už není dostupná. Ale za malou vzpomínku určitě stála.
Podívat se můžete i na video s ukázku práce se službou WAIS - s lokálním klientem a skrze WWW rozhraní. Přečíst si o ní můžete zde či zde.
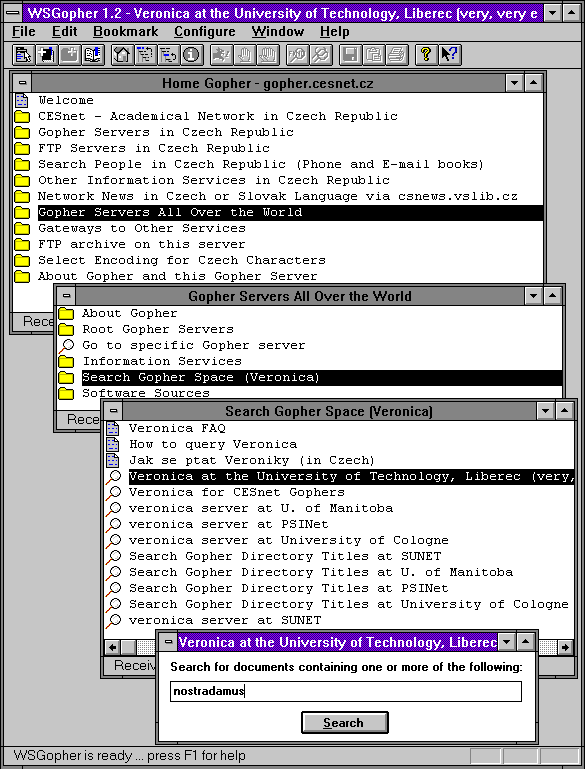
Veronica, Gopherova vyvolená
Poslední vyhledávací službou, o které se dnes zmíníme, je služba s půvabným dívčím jménem Veronica. Shlédnul se v ní Gopher a přijal ji "za svou" - učinil z ní svou vlastní (generickou) vyhledávací službu. Samozřejmě přístupnou skrze vlastní klientské prostředí (klienta i systém menu Gopheru), a se zobrazováním výsledků ve formě Gopherských menu. To je něco, k čemu se World Wide Web dodnes nedostal. Skrze web se sice dostanete k celé plejádě vyhledávacích služeb, ale žádná z nich (ani Google) není "tou pravou", "jedinou", resp. "tou vyvolenou".
Princip fungování služby Veronica byl v zásadě velmi jednoduchý: stačilo jí prohledávat textová menu, tvořící nabídky Gopheru, a nadpis (jméno) koncových položek, a pamatovat si jejich obsah. Uživatel, který se na Veroniku následně obrátil s nějakým dotazem, a jako odpověď dostal seznam položek menu (a event. i koncových textových položek), které vyhověly jeho dotazu.
Příklad vidíte na následujících dvou obrázcích. Na prvním je zadání dotazu jednomu konkrétnímu serveru služby Veronica (jednalo se o jediné klíčové slovo "Nostradamus"), a na druhém pak odpověď Veroniky: seznam položek menu a jmen (titulků) koncových položek, obsahujících toto klíčové slovo.
 | 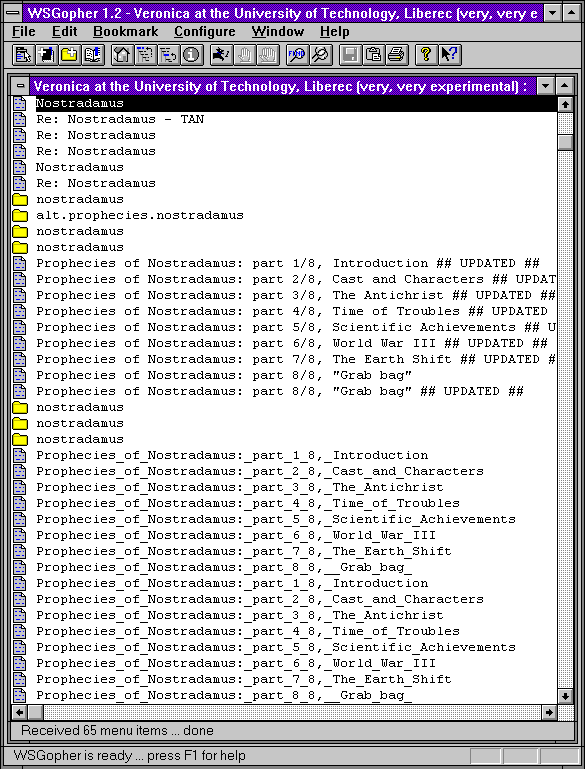 |
Veronika tedy nebyla fulltextovou vyhledávací službou v pravém slova smyslu, protože (standardně) nevyhledávala v samotných "koncových položkách" (byť jen těch, které měly textový charakter). Někdy to dělat mohla, ale primárně byla zaměřena na položky menu a na titulky (jména) koncových položek. Pokud bychom ji promítli do dnešního světa webu, pak by se jednalo o službu, která vyhledává v titulcích webových stránek (v položkách TITLE), a v textech které tvoří aktivní hypertextové odkazy (na které lze klikat, a které odpovídají položkám v menu Gopheru), ale nikoli už v samotném obsahu www stránek.
Příklad vidíte na následujících dvou obrázcích: na prvním je zadán dotaz tvořený klíčovým slovem "toulky", a výsledek poskytnutý službou Veronica: jde o odkaz na koncovou položku, v jejímž názvu (titulku) se hledané klíčové slovo vyskytuje. Na druhém obrázku jsou zobrazena data popisující příslušnou koncovou položku. Dnes bychom je asi označili za metadata. Text, nalezený na obrázku, vyhověl vyhledávacímu dotazu nikoli proto, že se klíčové slovo v jeho těle vyskytuje hned několikrát - ale proto, že se vyskytuje v jeho jméně, resp. titulku (položka Name).
 | 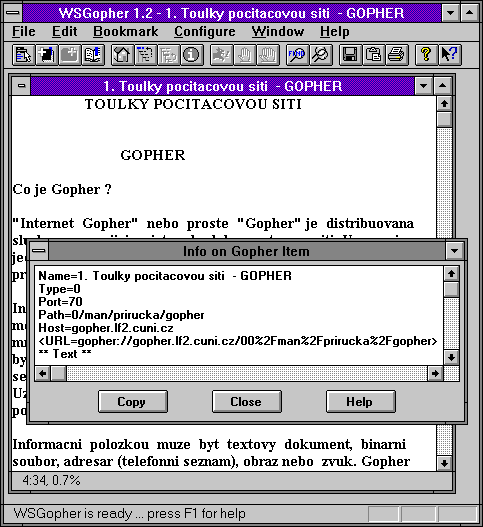 |
I když se tedy fungování služby Veronica zdá na první pohled zcela jednoznačné a nepřipouštějící žádné "stupně volnosti", přesto tato služba nebyla homogenní - nebylo jedno, kterého serveru jste se zeptali.
Existovaly různé servery služby Veronica, které se lišily zejména v tom, jak velký okruh Gopher serverů mapovaly (pravidelně "obcházely" a zjišťovaly obsah jejich nabídek). Odpověď různých serverů Veroniky se pak mohly i diametrálně lišit. Ukazují to ostatně i následující dva obrázky: na obou je stejný dotaz (tvořený klíčovým slovem "Nostradamus"), jako na prvním obrázku k Veronice (o dvě řady obrázků výše). Tam byl ale tento dotaz položen serveru Veroniky v Liberci, který našel řadu relevantních výsledků. Stejný dotaz, položený jinému serveru Veroniky (Veronica for CESnet Gophers, šlo zřejmě o server Cesnetu), vrátil pouze jediný odkaz (na soubor, v jehož popisu se klíčové slovo nacházelo).
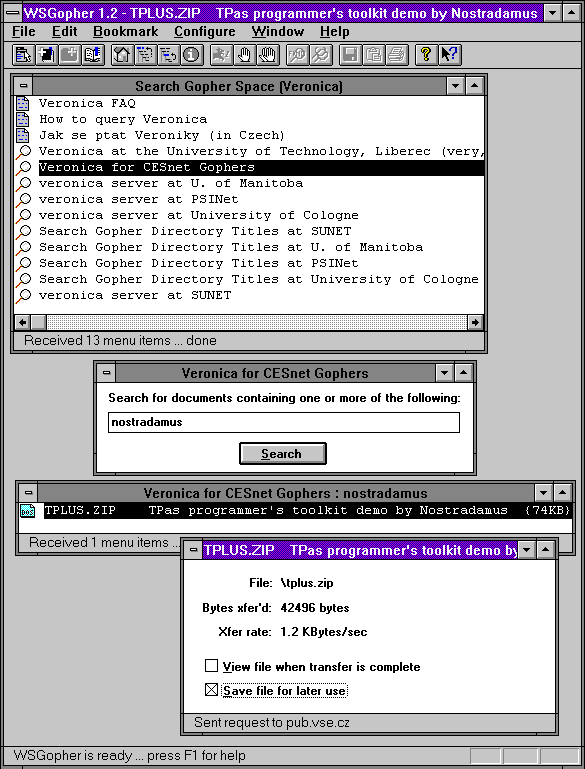 | 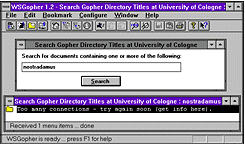 |
Zajímavý je také druhý z předchozích obrázků, který ukazuje výsledek stejného dotazu, směřujícího k serveru Veroniky v Kolíně (nad Rýnem). Ten nevrátil nic, a ohlásil že je zaneprázdněn. To ostatně byla bolest řady tehdejších Gopher serverů, které ještě nemohly mít "pod sebou" tak výkonné stroje, jako dnešní vyhledávací služby.
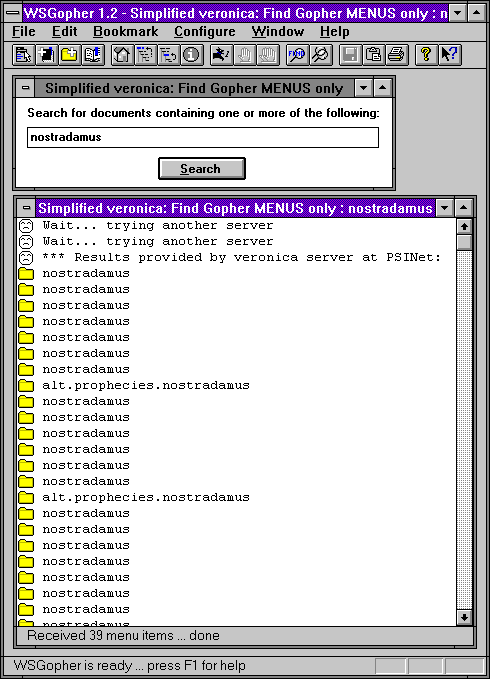
Řešením, které se časem našlo, byla tzv. zjednodušená Veronika (Simplified Veronica). Z dnešního pohledu to vlastně byla vyhledávací metaslužba, neboli služba která pouze "rozhazuje" přijímané dotazy mezi jiné servery, které pak skutečně odpovídají. Zjednodušená Veronika tyto servery vybírala podle jejich momentální vytíženosti. Výsledek ukazuje následující obrázek, na kterém jsou vidět první dvě odpovědi od zaneprázdněných serverů, a teprve za nimi relevantní odpovědi od serveru, který ještě měl volnou kapacitu pro další dotazy.
 |
Živou (video)ukázku vyhledávání pomocí služby Veronica můžete shlédnout zde.