


Báječný svět počítačových sítí
Část XV. : Výpočetní model
Většina aplikací, se kterými se můžeme setkat v prostředí dnešních počítačových sítí, vychází z výpočetního modelu klient/server. Není to ale zdaleka jediná možnost, protože vedle ní existovala a stále existuje celá řada zajímavých alternativ. Historicky nejstarší bylo tzv. dávkové zpracování, které ani dnes není zdaleka mrtvé. Následoval model host/terminál, po kterém přišly na řadu monolitické aplikace pro izolovaná PC. Jejich nedostatky řešilo propojení počítačů do lokální sítě a využití modelu file server/pracovní stanice. A jak vypadá a funguje 3-úrovňový model klient/server?V minulém dílu tohoto seriálu jsme si povídali o aplikační vrstvě a aplikacích, fungujících v prostředí počítačových sítí. Přitom jsme si již dopředu naznačili, že takovéto "síťové aplikace" dnes většinou vychází z modelu, označovaného jako klient/server. Jeho podstatou je rozdělení aplikace na dvě části - klienta a server - s tím že klient zajišťuje komunikaci s uživatelem, zatímco server vykonává "ostatní" funkce, potřebné pro vlastní běh aplikace. A také že obě složky (klient i server) mohou být vzdáleny od sebe a běžet na různých počítačích, vhodně propojených pomocí (jakékoli vhodné) počítačové sítě.
Jak ale již tušíte z perexu dnešního dílu, není to zdaleka jediná možnost toho, jak mohou aplikace fungovat, jak mají být řešeny (např. zda mají být rozděleny na několik částí či nikoli), kde mají mít svá data (a kde je mají zpracovávat), jak mají komunikovat s uživatelem atd. Obecně lze v této souvislosti hovořit o architektuře aplikací, ale zde se přidržíme přeci jen častějšího termínu "výpočetní model". Hlavně se ale seznámíme i s dalšími výpočetními modely, než je model klient/server.
Na počátku bylo dávkové zpracování
Výpočetní modely se samozřejmě s časem vyvíjí, a tento jejich vývoj je z jedné strany "tlačen" požadavky uživatelů, a z druhé strany je "usměrňován" možnostmi technologií, jak softwarových, tak i hardwarových. Historicky první výpočetní modely proto musely být relativně jednoduché a odrážet velmi skromné možnosti prvních počítačů.
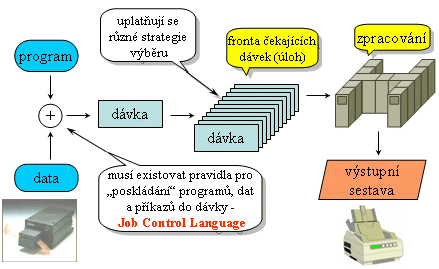
Zřejmě nejstarším výpočetním modelem je tzv. dávkové zpracování (anglicky: batch processing). To vzniklo v době, kdy počítače byly řízeny děrnými štítky či děrnými páskami, a ještě neměly žádné uživatelské terminály (coby pracoviště pro jednotlivé uživatele). Absence takovýchto terminálů pak nutně znamenala, že uživatelé nemohli být v přímém kontaktu se svými programy - nemohli jim zadávat žádné pokyny skrze klávesnici, myš apod., a také samotné programy nemohly svým uživatelům zobrazovat žádné výstupy (přes obrazovku). Takže třeba editace textů na počítači nebyla z principu možná, a žádné textové editory neexistovaly. Obecně tedy neexistovala možnost interakce, resp. tzv. interaktivita (mezi uživateli a jejich programy). No a tomu se samozřejmě musel přizpůsobit i tehdejší výpočetní model, tj. dávkové zpracování. To je dodnes antonymem (opakem) k interaktivitě.
Dávkové zpracování, které nemá k dispozici interaktivitu, nutí uživatele k tomu, aby všechny své požadavky na zpracování počítačem připravil a přesně vyspecifikoval dopředu. Tedy aby přesně a jasně popsal, který program má být spuštěn, s jakými vstupními daty má pracovat, kam mají být ukládána výstupní data, generovaná tímto programem, a případně jak se má pokračovat (v případě korektního zakončení programu či v případě chyby). Pokud tak uživatel učiní, a k popisu svých požadavků přidá samotný program i všechna vstupní data, vzniká tím tzv. dávka (anglicky: batch). Tu si lze představit jako určitý celek, který pak může být počítačem proveden (zpracován) v zásadě kdykoli, podle toho, "kdy má čas počítač" (a nikoli podle toho, "kdy má čas uživatel"). Jednotlivé dávky, od stejného uživatele i od dalších uživatelů, se obvykle řadily do front, kde čekaly, až na ně dojde řada a budou zpracovány. Uživatel mezitím čekal, třeba i několik hodin, nebo dokonce dnů, než se dočkal nějakého výsledku zpracování své dávky.
 |
Dávkové zpracování stále žije
Ačkoli dávkové zpracování vzniklo v určité historické době a reagovalo na tehdejší stav výpočetní technicky, není ještě zdaleka mrtvé. I dnešní operační systémy podporují dávky (dávkové soubory), skrze které lze dopředu připravit (naprogramovat) určité činnosti, a pak je jen ve vhodnou dobu spouštět.
Stejně tak se dnes dávkové zpracování používá třeba v souvislosti se superpočítači. Zde si uživatel (na svém osobním počítači) dopředu připraví svůj výpočet i s daty, které chce zpracovat - a pak vše "zabalí" do jedné dávky a tu pošle ke zpracování superpočítači. Už se tomu ale neříká ani tak dávkové zpracování, jako spíše Remote Job Entry (dálkové zadávání úloh), či Remote Job Execution (dálkové zpracování úloh). .
Model host/terminál
Touhu uživatelů po přímém kontaktu s jejich aplikacemi (interaktivitě) bylo možné splnit až v době, kdy se počítače začaly vybavovat vhodnými terminály, či spíše sítěmi terminálů. To proto, aby s počítačem mohlo pracovat více uživatelů. Jenže to nestačilo. Muselo se vhodně zařídit i to, aby se počítač "věnoval" všem těmto uživatelům současně. I to bylo novum oproti předchozímu dávkovému zpracování, kdy se počítač celou svou kapacitou věnoval vždy jen jedné úloze.
Řešení se nakonec našlo v technice, označované jako "sdílení času" (time sharing). Předpokládá, že počítač se vždy po určitou dobu věnuje jednomu uživateli, pak druhému, pak třetímu atd., a stále dokola. Ovšem ony "určité doby" jsou velmi krátké (např. desítky milisekund) a přepínání tak rychlé, že to jednotliví uživatelé ani nemají šanci postřehnout. Místo toho si mohou myslet, že se celý počítač věnuje právě a pouze jim.
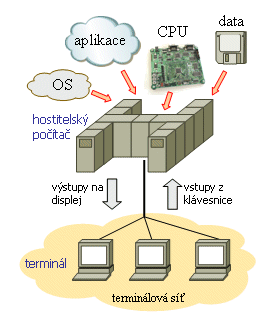
S využitím této techniky již bylo možné vyvinout nový výpočetní model, označovaný jako host/terminál. Pozor ale na to, že slůvko "host" v jeho názvu není odvozeno od českého slova "host" (ve smyslu: být hostem u někoho), ale od anglického "host", což v češtině znamená "hostitel", resp. "být hostitelem někoho, resp. něčeho". Takže je na místě mluvit o hostitelském počítači, který je "hostitelem" pro aplikace, ale i pro data, výpočetní kapacitu a další zdroje.
A právě to je pro celý model "host/terminál" typické a charakteristické - předpokládá, že veškeré zdroje jsou umístěny "na jedné hromadě" (na hostitelském počítači, a tedy centrálně), a zde se s nimi také pracuje. K jednotlivým uživatelům, na jejich terminály, pak "putují" již jen výstupy jednotlivých aplikací, zatímco opačným směrem proudí vstupy od uživatelů, určené jejich aplikacím (hlavně vstupy z klávesnic). Pokud vám to připomíná terminálové relace, popisované v minulém dílu tohoto seriálu, v souvislosti s Telnetem, pak vězte že podobnost opravdu není náhodná.
 |
Monolitické aplikace pro izolovaná PC
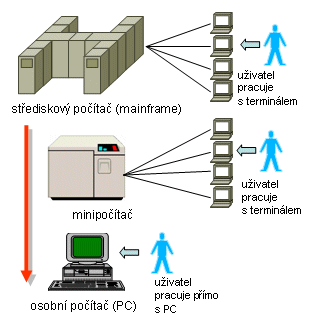
Pokrok a vývoj v oblasti hardwaru (i softwaru), který prvním počítačům postupně dopřál terminály (a model host/terminálů), se samozřejmě nezastavil, ale pokračoval dále. Nejprve se ubíral cestou zmenšování hostitelských počítačů, které původně byly opravdu velmi velké. Však se jim také říkalo "střediskové počítače", či převzatě z angličtiny "mainframy". Časem se ale zmenšily do podoby tzv. minipočítačů. Jejich fungování, na bázi modelu host/terminál, se ale nezměnilo, protože stále musely sloužit více uživatelům současně. A ti s nimi pracovali prostřednictvím terminálů.
Lidé ovšem toužili po tom, aby měli počítač jen a jen ke své dispozici, a nemuseli se o něj dělit s nikým jiným. Na to si museli ještě chvíli počkat, ale nakonec to přišlo také. Na trh se dostaly osobní počítače (počítače PC, Personal Computer), které za svůj přívlastek "osobní" vděčí právě tomu, že už mohou být přiděleny jednomu uživateli do výlučného použití. Jenže co s aplikacemi pro takovéto osobní počítače?
 |
Aplikace pro osobní počítače už nemusely počítat s tím, že jejich uživatelé nejsou na hostitelském počítači sami. Nemusely se tedy dělit o dostupné zdroje (výpočetní kapacitu, paměť atd.) s ostatními aplikacemi, které si provozovali ostatní uživatelé, a mohli se na osobním počítači chovat jako jeho výluční páni. Také nemusely čekat na to, ke kterému terminálu si sedne jejich uživatel, aby mu pak posílaly své výstupy právě na tento terminál. Mohly předpokládat, že jejich uživatel s nimi bude komunikovat přes jedinou klávesnici a jedinou obrazovku, kterou je osobní počítač vybaven. Takže měly vlastně o dost snazší pozici, mohly být relativně jednodušší, a mohly být koncipovány jako monolitické (ve smyslu: "v jednom kuse", nikoli nějak dělené).
Potřeba sdílení
Monolitické aplikace, určené pro osobní počítače, dokázaly nabídnout svým uživatelům poměrně vysoký komfort. Měly ovšem také své nevýhody. Například tu, že kdykoli bylo třeba udělat do nich nějaký zásah (například nahrát nějakou aktualizaci, novou verzi, nějaké nové nastavení atd.), muselo se vše dělat na každém počítači, pro každého uživatele. Obecně tedy n-krát, zatímco dříve, na hostitelském počítači a v rámci modelu host/terminál, stačilo vše udělat jen 1-krát. Nároky na systémovou správu a údržbu tedy obecně vzrostly n-krát, což se s postupem času ukázalo jako zásadní problém. Zejména ve firemním prostředí tím výrazně stouply náklady na podporu uživatelů (v rámci tzv. TCO, Total Cost of Ownership), a vynutily si určitý návrat k centralizovaným výpočetním modelům. Tedy k takovým, kde jsou aplikace více soustředěny na nějakém centrálním místě.
 |
Samostatné a vzájemně izolované počítače však měly ještě jednu principiální nevýhodu: neumožňovaly žádné sdílení. Například když více uživatelů chtělo pracovat se stejnými daty, nešlo to - a každému bylo třeba vytvořit a přidělit jeho vlastní kopii požadovaných dat. Něco takového už nešlo udělat například s drahými periferiemi, jako třeba s laserovými tiskárnami. Dát každému k dispozici kvalitní tiskárnu bylo i v době osobních počítačů zbytečným luxusem, místo kterého obvykle nastupovalo sdílení jedné tiskárny více uživateli.
Od extrému k extrému, nebo zlatá střední cesta?
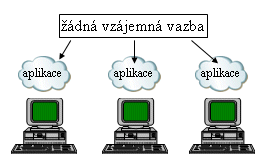
Izolované osobní počítače a jejich monolitické aplikace však nebyly připraveny na žádné sdílení svých zdrojů (včetně periferií). Samy vlastně představovaly jakýsi přeskok od jednoho extrému k extrému přesně opačnému: původní výpočetní model host/terminál totiž byl maximálně centralizovaný, kvůli tomu že všechny zdroje u něj byly soustředěny na jednom (centrálním) místě, na samotném hostitelském počítači. Takže sdílení zde bylo velmi snadné. U izolovaných osobních počítačů to ale bylo přesně naopak - všechny bylo plně distribuované, resp. decentralizované (rozdělené mezi jednotlivé uživatele, na jejich osobní počítače), a naopak nic nebylo společné. Žádné sdílení zde vlastně ani nešlo realizovat, protož nebylo jak.
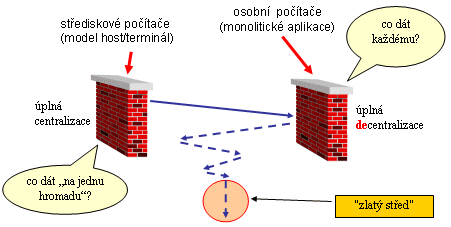 |
Lidé však záhy přišli na to, že ani jeden extrém není ideální, a jali se hledat zlatou střední cestu. Ta by v daném případě umožňovala sdílet to, co se hodí sdílet, a současně by umožnila přidělit každému do jeho výlučného vlastnictví a používání to, co se naopak sdílet nemusí. Sdílet by se mohly například periferie (již zmiňované tiskárny), nebo třeba datové soubory, ke kterým chce mít přístup více uživatelů. Jenže jak to udělat, když izolované počítače nebyly mezi sebou vůbec propojeny?
Model file server/pracovní stanice
Prvním krokem k možnosti sdílení bylo vhodné propojení do té doby izolovaných osobních počítačů. K tomu naštěstí již existovala vhodná technologie, vyvinutá právě pro takovýto účel. Ano, byl to Ethernet, nabízející přenosovou rychlost 10 megabitů za sekundu. To bylo dost na to, aby se alespoň sdílení souborů dalo realizovat transparentním způsobem. Tedy tak, aby z pohledu uživatelů a jejich aplikací "nebylo vidět", a soubory, fakticky umístěné na některém jiném počítači v síti, se mohly "tvářit" a chovat stejně jako soubory lokální, umístěné na daném počítači. Včetně toho, že když s nimi chtěl uživatel (nebo jeho aplikace) pracovat, netrvalo to o nic déle, než u skutečně lokálních souborů.
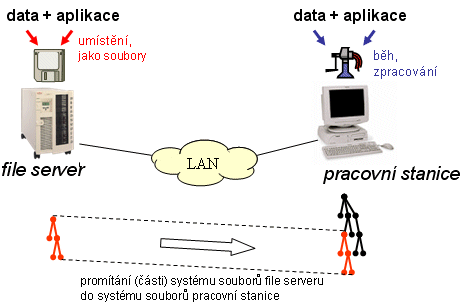 |
Jenže pro takovéto plně transparentní sdílení souborů, umístěných na jiném počítači, bylo třeba vymyslet také vhodné technické řešení. Takové, které by dovolilo umístit soubory na jedno centrální místo - na počítač, fungující jako tzv. file server, resp. souborový server - ale současně umožnilo ostatním počítačům v síti "vidět je" jako své vlastní soubory. Lze si to představit také tak, že systém souborů file serveru se "promítá" (tzv. mapuje) do systému souborů jiného počítače (tzv. pracovní stanice). Jde skutečně jen o iluzi, která ale naplňuje ušlechtilé cíle: díky ní mohou na pracovní stanici (osobním počítači) běžet monolitické aplikace, které vůbec nepočítají s existencí sítě a nějakých vzdálených počítačů (file serverů). Přesto dokáží pracovat s datovými soubory, které jsou ve skutečnosti umístěné na jiném uzlu sítě (ale vůči nim se tváří jako místní).
A dokonce: i tyto samotné aplikace, které o existenci sítě nic netuší, mohou být jako soubory umístěné centrálně, na file serveru, ale "promítat" se do souborového systému pracovní stanice (osobního počítače), a zde být jako aplikace spouštěny a provozovány. Tento jednoduchý trik pak značně zjednodušuje systémovou správu a údržbu těchto aplikací, protože tu lze realizovat na jednom centrálním místě (na file serveru, kde jsou aplikace uloženy jako soubory), místo na každém jednotlivém počítači.
Dodnes se stejné řešení, zde popisované jako "model file server/pracovní stanice", v praxi hojně používá, byť třeba pod úplně jinými jmény. Často se například mluví jen o tzv. síťových discích (vzdálených discích apod.), které plní roli file serveru. Má to i svou logiku: zde popisovaný "model file server / pracovní stanice" vlastně není ani žádným výpočetním modelem. Je zcela záměrně "neviditelný", právě proto aby se mu aplikace nemusely přizpůsobovat. Díky tomu bylo možné hned od začátku používat v prostředí sítě i takové aplikace, které o ní vůbec netušily a myslely si, že pracují na samostatném a izolovaném osobním počítači (který mají navíc samy pro sebe).
Model klient/server
Model file server/pracovní stanice, popisovaný v předchozím odstavci, tedy umožnil používat v prostředí sítě i takové aplikace, které na to nebyly stavěny. Nebylo to ale zadarmo. Každá taková aplikace, která o existenci sítě netušila, a byla (jako soubor) umístěna na centrálním file serveru, musela být při svém spuštění nejprve celá přenesena z file serveru na pracovní stanici. Staral se o to systémový software, zajišťující potřebné "mapování" systémů souborů (aniž si to uživatel a jeho aplikace uvědomovali). Obdobně pro datové soubory, se kterými taková aplikace pracovala - také ty se musely přenášet sem a tam, což mohlo výrazně zatěžovat celou lokální síť jako takovou. Jenže to rozhodně nebylo zadarmo. Byla s tím spojena nemalá režie.
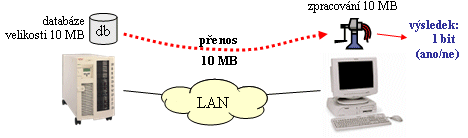
Zdrojem této režie zde byla skutečnost, že data se zpracovávala jinde, než kde byla umístěna. Pro docenění celého problému si jej můžeme ukázat na následujícím příkladu, v záměrně zveličené podobě: představme si databázi velikost například 10 MB, která má být prohledána, zda se v ní nenachází nějaká konkrétní data. Je úplně jedno jaká, ale podstatné je, že výsledkem je jednobitová informace: ano, nebo ne. Pokud je ale takováto databáze umístěna (jako soubor) na file serveru, ale díky modelu file server/pracovní stanice bude prohledávána na pracovní stanici, musí být před samotným prohledáním nejprve celá přenesena (z file serveru na pracovní stanici). Přeneseno musí být obecně všech 10 MB dat, které tuto databázi tvoří.
Teď si ale představme jiný scénář: databáze se prohledá tam, kde se nachází (na centrálním file serveru), a po síti se na pracovní stanici přenese jen jednobitový výsledek celého prohledání. Úspora přenosové kapacity je jasná a obrovská.
Jenže abychom mohli takovýto scénář realizovat, musíte nejprve přinutit tu aplikaci, která databázi prohledává, aby se "přestěhovala" z pracovní stanice přímo na centrální file server. Jenže pak zase nebude moci komunikovat s uživatelem. Takže jinak: rozdělíme aplikaci napůl, a jedna její část (zajišťující komunikaci s klientem) zůstane na pracovní stanici, zatímco druhá část (ta, která bude skutečně prohledávat databázi), se přestěhuje tam, kde se databáze nachází, tedy na centrální server. Ale to už jsme dospěli k výpočetnímu modelu klient/server, s kterým jsme se seznámili v minulém dílu tohoto seriálu.
 |
Zopakujme si tedy, že jde o výpočetní model, který již programové počítá s existencí sítě, resp. distribuovaného prostředí, a původně monolitickou aplikaci rozděluje na dvě části: klientskou a serverovou. Pomyslný "řez", který obě části oddělí, se snaží vést tak, aby komunikace mezi klientem a serverem byla co nejméně obsáhlá, tj. aby představovala co nejmenší objemy dat (kvůli zátěži přenosové sítě mezi klientem a serverem).
Server pak zajišťuje potřebné zpracování, které ale provádí vždy až na žádost ze strany klienta. Klient zase zajišťuje veškerou komunikaci s uživatelem - přijímá od něj pokyny, a naopak mu zobrazuje (prezentuje) výsledky zpracování, které zajistil server.
3-úrovňový klient/server
Model klient/server je v současné době zřejmě nejrozšířenější výpočetní model, hojně používaný v běžné praxi. To ale zdaleka neznamená, že by neměl žádné nedostatky a nevýhody, a že by od něj neexistovaly "lepší" verze.
Jednou z nevýhod modelu klient/server je to, že i jeho klientská část je "aplikačně závislá", tj. specifická pro danou aplikaci. To na první pohled nevypadá jako nějaká nevýhoda - ale zkusme si představit, že v reálném provozu uživatelé používají několik aplikací, a od každé z nich musí mít na svém počítači nainstalovaného příslušného klienta. A co navíc: o každého takového klienta se musí někdo starat (správce systému). Komplikované to ale je i pro samotného uživatele, protože i on se musí učit pracovat s několika různými klienty, kteří mohou mít různé způsoby a styly ovládání, úplně jinou logiku atd. Nebylo by tedy lepší, kdyby existoval jeden univerzální klient, který by byl využitelný pro více různých aplikací?
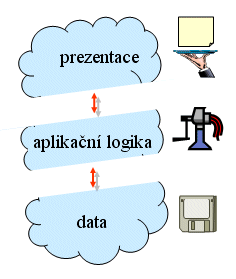
Myšlenka jednoho univerzálního klienta naštěstí není utopií, jak by se na první pohled mohlo zdát. Dokonce v praxi již existuje a používá se. Vyžaduje ale, aby se příslušná aplikace rozdělila nikoli na dvě části, jako u klasického modelu klient/server, ale hned na tři části. Proto se také mluví o "3-úrovňovém modelu klient/server". Jaké tři části to ale mají být?
Možnosti využít jediného univerzálního klienta se dosahuje tím, že se vyčlení (do samostatné části) vše, co je pro danou aplikaci specifické a unikátní. Tím vznikne "prostřední" část, které se ne nadarmo říká aplikační logika. Vedle ní se pak již dají použít dvě univerzální části:
- databázový server, který především uchovává aplikační data, a dokáže v nich vyhledávat (v praxi jde obvykle o běžný SQL server)
- prezentační část, která zajišťuje potřebnou "prezentaci" (zobrazování výsledků uživateli, a získávání vstupů od uživatele).
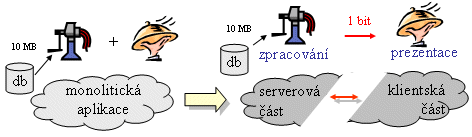 |
V praxi plní roli prezentační části nejčastěji běžný WWW prohlížeč (browser). Aplikační logika je pak "schována" za příslušným WWW serverem, a "z druhé strany" je na ni napojen databázový server. V roli praktického příkladu si představme třeba vyhledávání v jízdním řádu: všechny údaje o existujících spojeních jsou uloženy v databázovém serveru (SQL serveru), který v nich dokáže standardním způsobem vyhledávat (pomocí SQL příkazů). Nerozumí ale tomu, co jednotlivé údaje v databázi znamenají, jak spolu souvisí, jak na sebe jednotlivé spoje navazují atd. Všechny takovéto informace, specifické pro aplikaci spočívající ve vyhledávání spojení, jsou soustředěny v aplikační logice. Ta z jedné strany "rozumí" dotazům uživatelů, a "z druhé strany" rozumí datům, obsaženým v databázi. Dokáže tedy správně interpretovat dotazy uživatelů, hledat na ně odpovědi, a tyto odpovědi pak zase zpětně vracet uživatelům. Ovšem o prezentaci těchto výsledků už se stará prezentační část, "postavená" na WWW serveru a browseru. Uživatel klade své dotazy skrze webové stránky (kde zadá svůj dotaz v příslušném formuláři), a také odpovědi na své dotazy dostává v podobě webových stránek, které mu zobrazuje jeho prohlížeč.
 |
Nepotřebuje tedy žádného specifického klienta pro vyhledávání dopravních spojení, ale pro danou aplikaci (i další aplikace) vystačí jen s jedním klientem - běžným WWW prohlížečem. Navíc může takového univerzálního klienta použít skutečně kdekoli, po celém světě, v dosahu služby WWW.
Na závěr si jen zkusme představit, jak by to dnes vypadalo, pokud by neexistoval takovýto 3-úrovňový model klient/server, a pro každé trochu specializované vyhledávání na Internetu by byl zapotřebí samostatný klient!