


Proč kleknul NIX?
Výpadek NIXu z minulého týdne nebyl způsoben útokem ale závadou, která dala vzniknout jevu zvanému "broadcast storm". Přesná příčina není známa, stejně jako zařízení, které broadcast storm vyvolalo. Podobné příhody se bohužel stávají i jinde a nejde je úplně vyloučit. Náš NIX chce čelit možnému opakování přehodnocením pravidel pro připojování k peeringovému segmentu.Přesně před týdnem, v úterý 11. května v podvečer, se v českém peeringovém centru NIX odehrálo něco velmi nestandardního. Statistiky, ukazující vytížení přípojek jednotlivých členů, mezi 16 a 18 hodinou vylétly do závratných výšin.
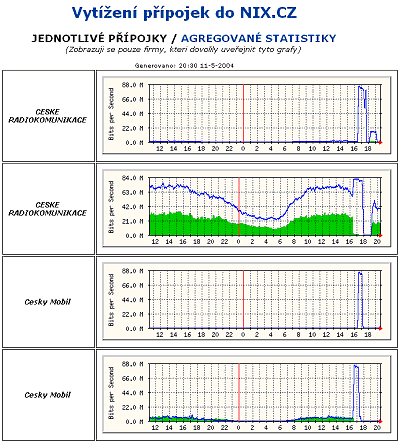 |
Zatímco statistiky ukazovaly takto extrémně zvýšený provoz, "užitečný" provoz skrze NIX naopak téměř neprocházel, a tak to na svých bedrech pocítili i koncoví uživatelé - někdo se svých dat nedočkal vůbec, a někdo si musel počkat podstatně déle než jindy.
První úvahy a spekulace o tom, co se vlastně v NIXu stalo, směřovaly cestou úvah o útoku typu DoS (Denial of Service). Tedy toho, že někdo cíleně bombardoval uzly NIXu svými požadavky, s cílem úplně je zahltit. Další verzí bylo to, že do jednoho ze čtyř peeringových středisek NIX-u (konkrétně do budovy Sittelu) uhodil blesk, a poškodil některá zařízení.
Konkrétní vysvětlení nenabízely ani maily, které někteří provideři rozesílali svým zákazníkům:
Vazeni zakaznici,
dnes 11.5.2004 v cca 16:30 doslo k poruse L2 infrastruktury ceskeho peeringoveho centra NIX a nasledkem toho k preruseni vzajemneho propojeni vsech operatoru. Vysledkem byl temer 90ti minutovy vypadek celeho ceskeho internetu. Za problemy se omlouvame, bohuzel chyba nebyla na nasi strane a ani nesla nijak jednoduse odstranit. V kooperaci s ostatnimi operatory byla situace vyresena kolem 18. hodiny, na zjistovani pricin se nadale pracuje - dalsi komplikace by jiz nastat nemely...
Podle informací, které se mi podařilo z NIXu získat, nešlo o žádný útok zvenčí, ale o specifickou závadu některého ze zařízení v NIXu, která vyvolala tzv. broadcast storm. Ten pak zahltil prakticky všechny přípojky členů NIX-u, a skončil až tím, že se příslušná zařízení různě povypínala, odpojila atd.
Pro toho, kdo se nechce moc zabývat detaily, si dovolím připodobnit "broadcast storm" ke slovní přestřelce, či tzv. "flame war" (v diskusích): někdo nadhodí do pléna něco, co všechny ostatní nadzdvihne ze židle a okamžitě na to reagují stejně ostře. Každý pak z plna hrdla křičí na všechny ostatní (generuje velký datový provoz, viz statistiky), a odmítá s tím skončit. Nepomůže nic jiného, než násilné "zavření úst" (odpojení, restart atd.).
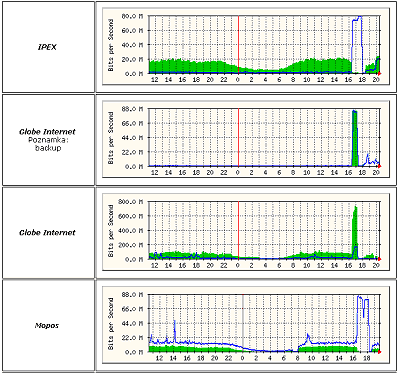
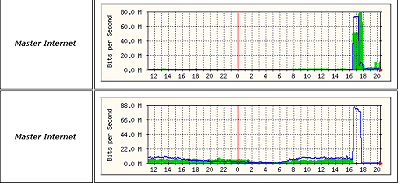
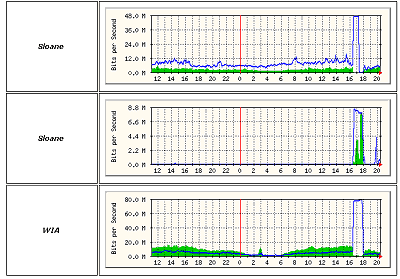
Co přesně se odehrálo na začátku, a kdo byl iniciátorem přestřelky (čí zařízení způsobilo vznik broadcast storm-u), se mi zjistit nepodařilo. Zdroje z NIXu jsou v tomto ohledu velmi diplomatické a říkají, že se to nedá stoprocentně určit. Hypotéz je více, některé hovoří o čistě technické závadě, jiné zase o poškození v důsledku úderu blesku. Zajímavé jsou i samotné statistiky z doby "přestřelky":
 |
 |
 |
Zákonitá otázka, která se okamžitě nabízí, je to zda se podobné příhody občas stávají, nebo zda je to něco nevídaného a unikátního. Odpověď je taková, že zcela unikátní to není, a že přes veškerou péči a snahu o předcházení k tomu dochází i v jiných peeringových centrech. Například zde je popisován obdobný příklad, který se stal v říjnu roku 2001 ve Velké Británii, tamnímu peeringovému centru LINX. Také tehdy to ovlivnilo většinu provozu v celé zemi, a první reakce také byly takové, že někdo atakuje LINX útokem DOS (viz zde). Nakonec se ale ukázalo, že i zde to byl "broadcast storm".
Podle informací z našeho NIXu to ani u nás nebylo úplně poprvé. I v minulosti s prý vyskytly "broadcast storms", ale nikdy nebyly tak rozsáhlé. Vždy se je podařilo eliminovat, tak aby neměly výraznější dopady na český Internet a provoz v něm.
Důvody toho, proč "broadcast storm" v peeringových centrech vzniká, je třeba hledat ve způsobu jejich technického řešení. Náš NIX se v tomto ohledu nijak neliší od ostatních ve světě: všechny přípojky jednotlivých operátorů (členů NIX-u) jsou propojeny na úrovni linkové vrstvy (druhé vrstvy ISO/OSI modelu, tj. L2). Navzájem si tedy vyměňují linkové rámce (konkrétně ethernetové), způsobem který je označován jako switching. Zařízení, které tak činí, je tzv. switchem. Náš NIX používá switche řady Catalyst od firmy Cisco, konkrétně modely 3550, 6006, 6506. V každém ze čtyř současných propojovacích bodů NIX-u (v objektech ČRa, GTS, Pragonetu a Sitelu) je umístěn takovýto switch, a všechny jsou vzájemně propojeny (topologie).
Tímto propojením switchů (na úrovni linkové vrstvy) vzniká jedna velká ale "plochá" IP síť, která tudíž tvoří jedinou broadcast doménu: kdykoli někdo vyšle tzv. broadcast (rámec určený všem), všechny switche jej musí rozeslat do všech směrů (do všech přípojek, které jsou na ně napojeny). Takže pokud nějaké zařízení začne rozesílat zvýšené množství broadcastů, začne tím významně zatěžovat celou síť (celou soustavu vzájemně propojených switchů). Pokud přitom ještě udělá chybu a rozesílá broadcastový rámec s chybným obsahem, na který příjemce reaguje také broadcastem, vzniká okamžitě řetězová reakce, která prudce eskaluje a téměř okamžitě zahltí veškerou dostupnou kapacitu - a právě to je tzv. broadcast storm.
Nebezpečí vzniku broadcast storm-ů je v odborné literatuře běžně uváděno jako jeden z argumentů, proč není dobré dělat "příliš velké" sítě jen pomocí switchů - právě proto, že tím vzniká příliš velká broadcastová doména, která musí šířit všechny broadcasty do všech svých částí. Obecným řešením je rozbít takovouto příliš velkou síť na menší části a učinit z nich samostatné sítě, a tím i samostatné broadcast domény (a vzájemně je propojit na úrovni síťové vrstvy, tedy pomocí směrovačů).
Takovéto obecné řešení by teoreticky připadalo v úvahu i pro realizaci peeringových center. Představovalo by ovšem větší zátěž na aktivní síťové prvky (směrovače místo switchů), bylo by pomalejší a také dražší. Pokud je mi známo, snad se ani nikde v peeringových centrech nepoužívá.
Dalším řešením, které připadá v úvahu, je ponechat společný segment, zajišťující peering, na úrovni vrstvy linkové, ale každou přípojku povinně "protáhnout" přes samostatný směrovač. Ten by pak mohl eliminovat případné problémy s broadcasty, ale i on bude hodně zatížen, bude drahý, bude zpomalovat přenosy - a také on se může "zbláznit" a vyvolat nějaké problémy. Absolutně spolehlivé řešení neexistuje (kromě úplného rozpojení).
Informace z NIXu hovoří o tom, že snahy zabránit eventuelnímu opakování události z minulého týdne se ubírají hlavně cestou přehodnocení (dosud skutečně dosti liberálních) pravidel toho, jak se členové NIXu připojují ke společnému (peeringovému) segmentu.