


NFS II.
V minulém dílu jsme si začali podrobněji popisovat myšlenky a principy, na kterých je založen protokol NFS (Network File System), vyvinutý firmou Sun Microsystems. Nejprve jsme se věnovali bezestavovému charakteru celého protokolu a tomu, co z této jeho bezestavovosti vyplývá. Dnes se zaměříme na další zajímavé aspekty, které nám umožní pochopit, jak tento velmi populární protokol funguje "uvnitř".
Nejprve si ale znovu připomeňme další významnou charakteristiku protokolu NFS, která jeho tvůrcům ležela velmi na srdci - a to možnost implementovat tento protokol na různých platformách, v prostředí nejrůznějších operačních systémů. Bezestavový charakter protokolu NFS tomuto požadavku vychází vstříc mj. tím, že zcela záměrně klade minimální nároky na schopnosti a spolehlivost přenosových protokolů, a dokáže vystačit prakticky s jakýmkoli přenosovým protokolem, který je k dispozici.
Požadavek na snadnou implementaci v různých prostředích, resp. na různých platformách, se ovšem netýká jen klientů, ale samozřejmě také serverů. Dnes je vcelku běžné, že v roli file serverů systému NFS vystupují také různé ne-Unixovské počítače. Například střediskové počítače IBM s operačním systémem VM mohou být vybaveny protokoly TCP/IP včetně NFS, a stejně tak může v roli NFS serveru vystupovat například i server systému Novell NetWare - k tomu stačí zakoupit a nainstalovat na NetWare serveru doplňkový program, tzv. NetWare NFS. Ten sice není zdaleka zadarmo, ale pokud lze věřit reklamním sloganům firmy Novell, vyjde toto řešení laciněji, než tradiční Unixovský počítač v roli NFS serveru.
Jestliže tedy protokol NFS může být implementován v prostředí různých operačních systémů, pak se nutně musí nějakým způsobem vyrovnat s jejich odlišnostmi. O tom, jaká může být povaha těchto odlišností, jsme si již něco naznačili v 70. dílu - na příkladu odlišností mezi Unixem a MS DOSem. Tvůrci protokolu NFS se se všemi potenciálními odlišnostmi rozhodli vyrovnat zajímavým způsobem: koncipovali samotný protokol NFS tak, aby se jej tyto odlišnosti vůbec netýkaly (a ošetření těchto odlišností svěřili jiným protokolům, které stojí mimo NFS).
Pouze přes systémovou identifikaci
Jedním z důsledků tohoto přístupu je skutečnost, že samotný protokol NFS nikdy nepracuje s přístupovými cestami. NFS serveru nemůže jeho klient zadat požadavek typu "načti X bytů ze souboru /usr/pet/file1.doc, počínaje pozicí Y", který určuje požadovaný soubor včetně přístupové cesty k němu. Důvodem je skutečnost, že různé operační systémy mohou používat různé konvence pro sestavování i pro formální zápis těchto přístupových cest. Obdobně je tomu i se jmény (a příponami) souborů - také zde používají různé operační systémy různé konvence.
Bylo by samozřejmě možné zavést nějakou jednotnou konvenci (například tu, kterou používá Unix), a pak zajistit případný převod z/do konvence, kterou používá konkrétní hostitelský operační systém. Tvůrci protokolu NFS se však rozhodli pro jiné řešení: pokud klient požaduje na serveru nějakou akci s určitým souborem, pak mu tento konkrétní soubor neurčuje jeho jménem, případnou příponou a přístupovou cestou, ale pomocí jednoznačného identifikátoru, který se označuje jako file handle (česky nejspíše: systémová identifikace), a je zcela nezávislý na jakékoli místní konvenci pro pojmenovávání souborů a sestavování přístupových cest.
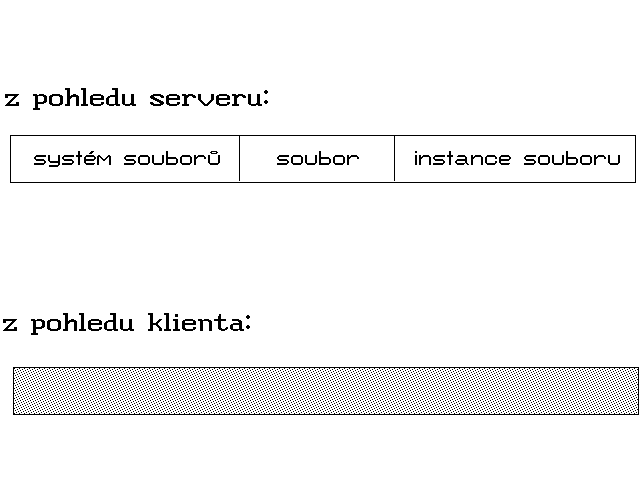 |
Konkrétní hodnotu jednotlivých bitů systémové identifikace samozřejmě určuje server, zatímco klient tuto identifikaci pouze používá, a chápe ji jako jediný, dále nedělitelný celek. Systémové identifikace, jednoznačně určující konkrétní soubory, pak ovšem musí klientovi poskytovat server, protože pouze on je dokáže vytvořit. Podívejme se nyní na formu, jakou se tak děje. Nejprve si ale řekněme, že systémová identifikace (file handle) může reprezentovat jak konkrétní soubor, tak i adresář.
Nyní si již představme situaci, kdy klient má k dispozici systémovou identifikaci nějakého konkrétního adresáře. Jednou z operací, kterou může na serveru požadovat, je vypsání jmen všech souborů (a podadresářů) v tomto adresáři (tj. v tom, od kterého již klient vlastní systémovou identifikaci). Server mu vrátí seznam znakových řetězců a různých příznaků, ze kterých lze mj. poznat, zda znakový řetězec je jménem souboru či jménem podadresáře. Jestliže se pak klient rozhodne pracovat s nějakým konkrétním souborem v tomto adresáři, musí nejprve získat jeho systémovou identifikaci. To udělá prostřednictvím další možné operace, kterou si vyžádá na serveru, a které předá jako vstupní parametr jednak systémovou identifikaci adresáře, a dále řetězec se jménem souboru, který získal při předcházejícím výpisu obsahu tohoto adresáře. Stejně bude klient postupovat i v případě, kdy bude potřebovat systémovou identifikaci některého z podadresářů daného adresáře.
Jak tomu ale bude v případě, kdy klient potřebuje "projít" částí adresářového stromu, aby se dostal k nějakému konkrétnímu souboru? Zde je dobré si znovu explicitně zdůraznit, že vzhledem ke svému bezestavovému charakteru nemůže mít protokol NFS žádnou analogii "aktuálního adresáře", ve kterém by se klient mohl nacházet. Klient však může vlastnit systémové identifikace jednoho či několika adresářů, a má k dispozici mechanismy, pomocí kterých může získávat systémové identifikace i jejich podadresářů (či naopak nadřazených adresářů). Tímto způsobem se může postupně dopracovat až k systémové identifikaci adresáře, ve kterém se nachází požadovaný soubor, a získat také jeho systémovou identifikaci. Musí si ovšem sám postupně vybudovat "představu" příslušného adresářového stromu, protože server mu nabízí vždy jen pohled na jedno patro (resp. jednu úroveň) tohoto stromu.
Kde začít
Jakmile tedy klient vlastní systémovou identifikaci alespoň jednoho adresáře nějakého adresářového stromu, dokáže si jejím prostřednictvím získat systémové identifikace všech ostatních adresářů a souborů v daném adresářovém stromu, který mu jeho server zpřístupňuje. Důležité je přitom to, že server nikdy nepotřebuje sestavovat jména adresářů do celé přístupové cesty, a ani k nim připojovat jména souborů s jejich případnými příponami. Klientovi předává pouze jednorozměrné znakové řetězce, a ponechává na něm, zda a jak si je bude sestavovat do větších celků.
Zajímavou otázkou je ale to, jakým způsobem klient získá onu první systémovou identifikaci. Zde je dobré si uvědomit, že server nabízí svým klientům vždy celé adresářové stromy, které se v Unixové terminologii označují jako souborové systémy (file systems). Každý server vždy "zveřejňuje" seznam těchto souborových systémů (tzv. je exportuje), a každý klient si z nich může vybrat ty, které si pomocí operace mount připojí ke svému globálnímu adresářovému stromu (pokud je sám Unixovským počítačem), resp. které si zpřístupní jako samostatná logická zařízení (jde-li např. o klienta, který pracuje pod operačním systémem MS DOS) - jak jsme si podrobně popisovali v 74. dílu seriálu.
Konkrétní postup "připojování" je takový, že klient si nejprve vybere ze seznamu souborových systémů exportovaných určitým serverem ten, který jej zajímá, a pak tomuto serveru vyšle požadavek na jeho připojení (provedení operace mount). Položky seznamu přitom tvoří jména kořenů jednotlivých adresářových stromů (souborových systémů), včetně přístupových cest k nim. Požadavek na připojení (mount), který klient adresuje serveru, tudíž obsahuje jména včetně přístupových cest, a nutně tedy musí používat nějakou konvenci pro jejich sestavování. Požadavek klienta ovšem není adresován přímo té entitě, která implementuje NFS server. Jejím adresátem je tzv. mount server (doslova: připojovací server), který není součástí NFS, a který již musí být uzpůsoben konkrétní konvenci pro pojmenovávání adresářů a sestavování přístupových cest, používané v prostředí, ve kterém je server implementován.
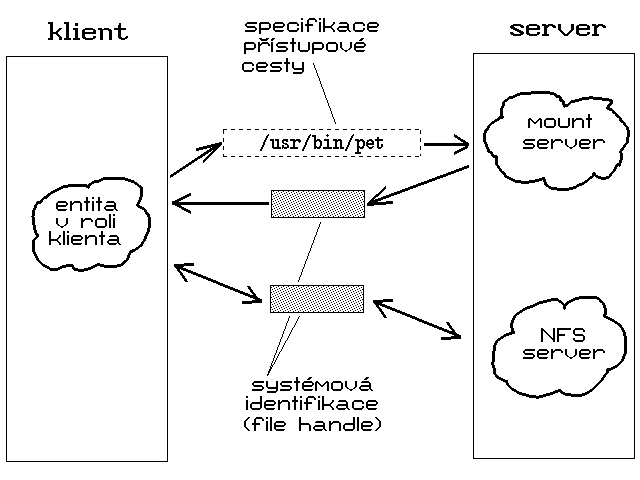 |
V tuto chvíli se ale nutně vnucuje otázka, proč je tomu právě takto? Jaká je logika v tom, že tzv. mount server není součástí NFS serveru (a způsob jeho činnosti není definován protokolem NFS)?
Důvody jsou především praktické. Služby mount serveru jsou využívány relativně velmi zřídka (typicky jednorázově při spuštění operačního systému klienta, který si v rámci svého startu připojuje souborové systémy serveru). Naopak služby NFS serveru mohou být využívány velmi často (při všech operacích se vzdálenými soubory). Na implementaci NFS serveru jsou proto kladeny velmi velké nároky, pokud jde o jeho rychlost, zatímco v případě mount serveru není jeho rychlost rozhodující. V prostředí Unixu je proto NFS server implementován jako součást jádra (aby mohl být co možná nejrychlejší), zatímco mount server může být implementován mimo jádro operačního systému, na stejné úrovni, jako běžné aplikační úlohy. Takovéto programy se ale píší a hlavně ladí mnohem snáze, než systémové programy, které mají být součástí jádra.
Mount server ovšem plní i některé další úkoly, než jen převádět jména adresářů včetně přístupových cest na systémové identifikace. Je to právě on, kdo skutečně "zveřejňuje" jména souborových systémů, exportovaných serverem. Má také za úkol ověřovat identitu uživatelů, kteří si ze svých počítačů v roli klientů připojují souborové systémy, a dále má i kontrolovat dodržování přístupových práv k exportovaným souborovým systémům. Díky tom, že si pro každého uživatele udržuje seznam jeho požadavků na připojení souborových systémů, je mount server nutně stavový (na rozdíl od bezestavového NFS serveru). Charakter stavové informace, kterou si mount server udržuje, však není kritický pro správné fungování NFS serveru i jeho klientů. Její význam je spíše pomocný, a využívá se například k tomu, aby server mohl včas varovat všechny své klienty o tom, že bylo zahájeno jeho řádné ukončení (tzv. shutdown).