


Transportní protokoly TCP/IP - II.
V minulém dílu našeho seriálu jsme se začali zabývat transportní vrstvou síťového modelu TCP/IP. Seznámili jsme se se dvěma alternativními protokoly - TCP a UDP - které jsou na této úrovni k dispozici, a zabývali jsme se především jejich odlišnostmi. Dnes se podrobněji zastavíme u toho, co mají oba transportní protokoly společného.
Až doposud jsme v našich úvahách předpokládali, že prvotními odesilateli a konečnými příjemci nejrůznějších dat v počítačových sítích jsou jednotlivé uzlové počítače jako takové. Nyní si však musíme tuto představu upřesnit: skutečnými odesilateli a příjemci jsou entity aplikační vrstvy. Tyto mohou být označovány různě: jako procesy (processes), úlohy (tasks), aplikační programy (application programs) či ještě jinak. Podstatné ovšem je, že v prostředí víceúlohových operačních systémů takovýchto entit může být (a také bývá) více. Oba protokoly transportní vrstvy pak potřebují podle něčeho rozhodnout, které entitě aplikační vrstvy mají přijatá data předat.
Adresy procesů?
Nejjednodušší by bylo adresovat jednotlivá data přímo konkrétním procesům. Tedy přidělit procesům jednoznačné identifikátory, a ty pak používat pro určení koncových příjemců v rámci příslušného hostitelského počítače. Problém je ovšem v tom, že procesy vznikají a zanikají dynamicky, a odesilatel obvykle nemá dostatek informací o tom, které konkrétní procesy právě běží na cílovém počítači. Kdyby tomu tak mělo být, při vzniku či zániku každého procesu by museli být průběžně informováni všichni potenciální odesilatelé, což není prakticky možné. Pro odesilatele navíc nemusí být vůbec podstatné, který konkrétní proces bude příjemcem jeho dat. Data, která proces na jednom počítači posílá na jiný počítač, totiž mohou představovat požadavek na určitou službu. Pak ale není relevantní to, který proces právě zajišťuje danou službu, jako spíše to, o jakou službu jde. Navíc je docela dobře možné, že jeden a tentýž proces zajišťuje více jak jednu službu současně.
Adresovat data konkrétním procesům tedy není příliš
rozumné. Jaké jsou ale alternativy?
Porty a jejich vlastnosti
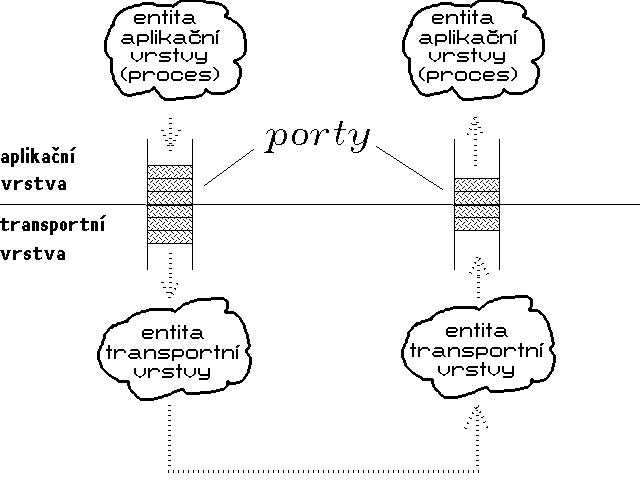 |
Síťový model TCP/IP používá právě tento mechanismus, a příslušné "přechodové body" označuje jako porty (ports).
Z pohledu procesu, který je právě připojen k určitému portu, se tento jeví jako vyrovnávací paměť s režimem fronty - entita transportní vrstvy ukládá data do portu z jedné strany, a entita aplikační vrstvy (tj. proces) si je ve stejném pořadí zase odebírá - viz obr. 55.1. Analogicky i pro opačný směr přenosu. Samotný port s právě naznačenými vlastnostmi je sám o sobě datovou strukturou, a jako takový může dynamicky vznikat i zanikat, obdobně jako vlastní procesy.
Adresy portů
Vztah mezi portem a procesem (entitou aplikační vrstvy) je vztahem dynamickým - procesy se dynamicky připojují a odpojují od jednotlivých portů. Pro odesilatele je tedy podstatné znát čísla (adresy) jednotlivých portů, a nemusí pro ně být relevantní, který konkrétní proces je k příslušnému portu právě připojen. Chce-li například určitý proces na hostitelském počítači A získat soubor, který se nalézá na počítači B, musí svůj požadavek na tento soubor adresovat počítači B (který určí jeho IP adresou), a doplnit jej adresou portu, na kterém je zajišťována služba pro přenos souborů. Adresy portů jsou přitom celými čísly bez znaménka, v rozsahu 16 bitů.
Otázkou ovšem je, jak může aplikační proces na jednom hostitelském počítači zjistit potřebná čísla portů na jiném počítači, ať již chce využít některou z jím poskytovaných služeb, nebo jinak komunikovat s některým z aplikačních procesů na tomto jiném počítači.
K řešení této otázky jsou v zásadě dva možné přístupy. První z nich spočívá v tom, že čísla portů se na všech hostitelských počítačích přidělí jednou provždy a stejně, a toto přidělení se zveřejní. Každý aplikační proces pak má k dispozici informaci o číslech příslušných portů na všech uzlových počítačích - těmto portům se pak také říká dobře známé porty (well-known ports). Problém je ovšem v tom, že tato varianta statického charakteru se dá použít jen pro zveřejnění takových služeb, které jsou předem známy, a s jejichž existencí lze předem počítat.
Alternativou je umožnit procesům na jiných uzlových počítačích zjistit si číslo portu na daném počítači - dotazem stylu: "na jakém portu je poskytována služba přenosu souborů?" Tato varianta stále vyžaduje alespoň jeden "dobře známý port" (přes který by bylo možné vznést příslušný dotaz), a je také spojena s určitou režií. Na druhé straně je ale mnohem pružnější, neboť umožňuje vytvářet porty a přidělovat jim čísla (adresy) podle okamžité potřeby dynamicky vznikajících a zanikajících aplikačních procesů, a není vázána tím, jak jsou obdobná přidělení realizována na jiných uzlových počítačích.
Tvůrci TCP/IP protokolů se rozhodli pro kombinaci obou variant - pro nejčastěji používané služby použili první možnost, tedy pevné přidělení čísel "dobře známým portům", a zbylé adresy ponechali volné pro dynamické přidělování podle okamžitých potřeb.
Multiplex a demultiplex datagramů
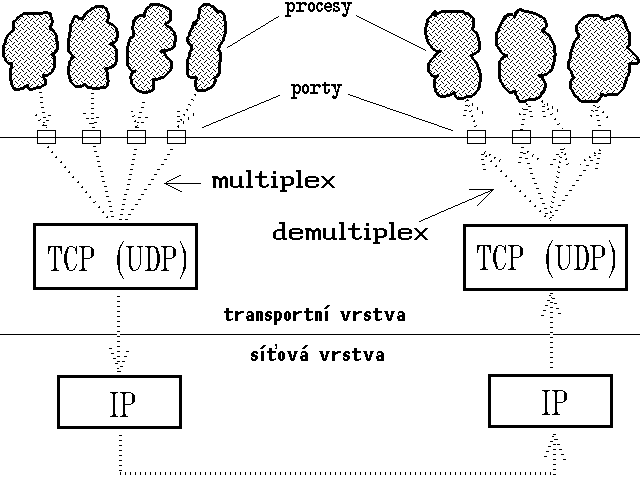 |
Tato představa velmi dobře odpovídá koncepci nespojované přenosové služby, kterou poskytuje protokol UDP. Tento protokol se na každý port dívá skutečně jako na jeden logický objekt - frontu, do které jsou postupně ukládány všechny datagramy, adresované tomuto portu na daném počítači.
Protokol TCP však vychází z poněkud odlišné abstrakce.
Vzhledem ke svému spojovanému charakteru pracuje se
spojeními, která jsou definována dvěma koncovými body
- každý koncový bod je přitom určen dvojicí