


Prezentační vrstva
Pět nejnižších vrstev referenčního modelu ISO/OSI dělá vše pro to, aby přenášená data vždy dorazila ke svému koncovému příjemci přesně v takové podobě, v jaké byla vyslána. Stejná "podoba" však ještě nezaručuje, že pro příjemce nebudou jedna a tatáž data představovat něco jiného, než pro jejich odesilatele.Obavy z různé interpretace přenášených dat nejsou zdaleka bezdůvodné. Stačí si uvědomit, že např. střediskové počítače firmy IBM používají pro kódování znaků kód EBCDIC, zatímco drtivá většina ostatních používá ke stejnému účelu kód ASCII. Ke znázornění celých čísel se znaménkem používá většina počítačů tzv. dvojkový doplňkový kód, ale např. počítače CDC Cyber pracují s tzv. jedničkovým doplňkovým kódem. Mikroprocesory 80x86 firmy Intel číslují jednotlivé byty (ve slovech, dvojslovech atd.) jedním směrem, zatímco například mikroprocesory řady M68000 firmy Motorola číslují jednotlivé byty přesně opačně. Velmi časté jsou pak také odlišnosti například ve formátu čísel v pohyblivé řádové čárce, odlišné rozsahy zobrazitelných celých čísel (dané počtem k tomu vyhrazených bitů) apod.
Různé počítače tedy v obecném případě používají různé způsoby vnitřní reprezentace dat. Mají-li si takové počítače svá data korektním způsobem vzájemně předávat, musí být vhodným způsobem zajištěny jejich nezbytné konverze. A ty má v referenčním modelu ISO/OSI na starosti právě prezentační vrstva (presentation layer).
Prezentační vrstva se tedy stará o to, aby například celé číslo bez znaménka s hodnotou 234 bylo přijato opět jako celé číslo bez znaménka s hodnotou 234, a ne např. jako celé číslo se znaménkem s hodnotou -22. Není však již úkolem prezentační vrstvy zabývat se tím, co toto číslo znamená. Zda jde např. o počet osob, o číslo stránky v knize, o procentuální výši inflace či něco docela jiného. To přísluší až vlastním aplikacím, které jsou zdrojem resp. příjemcem těchto dat.
 |
Referenční model ISO/OSI předpokládá právě tuto druhou variantu se společným mezitvarem. Podívejme se proto na její podstatu poněkud podrobněji.
Chtějí-li vzájemně spolupracovat dvě různé síťové aplikace, musí se nejprve domluvit na společných datových strukturách, které budou používat - tedy například na tom, že datum budou reprezentovat jako záznam (record) tvořený třemi položkami (DEN, MESIC a ROK), které jsou samy o sobě celými čísly bez znaménka. Tyto datové struktury je ovšem nutné vyjádřit tak, aby jejich popis byl pro obě strany srozumitelný, a obě strany si jej také stejně vykládaly. Kdyby byly všechny síťové aplikace psány v jediném vyšším programovacím jazyku, stačilo by použít právě tento jazyk. Předpoklad použití jediného programovacího jazyka však nebyl, není a zřejmě nikdy nebude v praxi splněn, a tak bylo nutné vytvořit pro potřeby formálního popisu dat a datových struktur zvláštní jazyk, který byl nazván ASN.1 (Abstract Syntax Notation). Umožňuje definovat jednotlivé datové položky, stanovit jejich typ (tj. určit, zda jde např. o celé číslo se znaménkem, znakový řetězec či logickou hodnotu apod.), přidělit jim jméno (identifikátor), a také sestavit z jednoduchých datových položek obecnější datové struktury typu záznam, pole, seznam, množina apod.
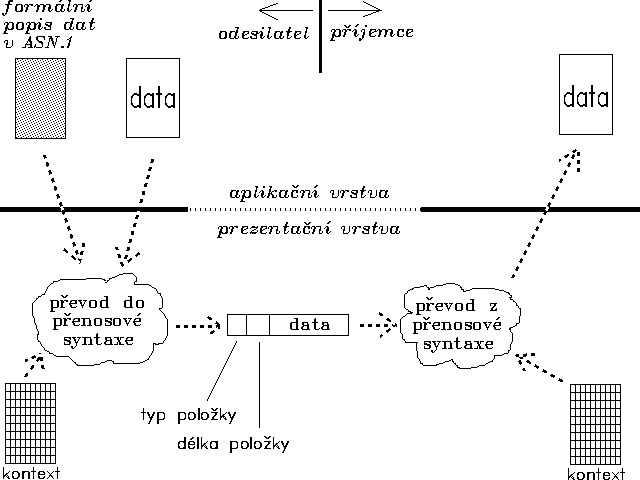 |
Způsob fungování prezentační vrstvy názorně ilustruje obrázek 37.2. Kdykoli chce nějaká entita aplikační vrstvy zaslat určitá data své partnerské entitě na jiném uzlovém počítači, předá "své" prezentační vrstvě jednak vlastní data, která si přeje odeslat, a jednak jejich popis v jazyce ASN.1 (který definuje jejich abstraktní syntaxi). Prezentační vrstva na základě tohoto popisu dokáže správně interpretovat jednotlivé položky dat (určit mj. jejich typ a velikost), a na základě toho je pak zakódovat do takového tvaru, který je vhodný pro přenos, a který si sebou nese potřebné informace o typu a formátu přenášených dat (tj. převést je do přenosové syntaxe). Prezentační vrstva na straně příjemce pak díky tomu dokáže správně určit typ a formát přijatých dat, a v případě potřeby provést nezbytné konverze. Jestliže například přenosová syntaxe počítá s vyjádřením celých čísel se znaménkem ve dvojkovém doplňku, ale příjemce používá ke stejnému účelu jednotkový doplněk, může prezentační vrstva příjemce provést nezbytné konverze ještě dříve, než přijatá data předá své bezprostředně vyšší (tj. aplikační vrstvě).
Prezentační vrstvy příjemce a odesilatele se však nejprve musí shodnout na tom, jaké datové struktury si vlastně budou předávat, a jakou budou pro ně používat přenosovou syntaxi. Proto se musí obě strany na začátku vzájemného spojení (přesněji: při zahajování relace) nejprve dohodnout na jednom nebo několika tzv. kontextech, jak se v terminologii ISO/OSI modelu nazývá přiřazení přenosové syntaxe k syntaxi abstraktní. V průběhu relace se pak mohou mezi těmi kontexty, na kterých se oba dohodli, dokonce přepínat.
 |
Hlavním úkolem prezentační vrstvy je tedy zajištění nezbytných konverzí přenášených dat. Není to ovšem úkol jediný - na úrovni prezentační vrstvy může být například řešeno také zabezpečení přenášených dat pomocí šifrování (encryption), které ovšem lze realizovat i na úrovni fyzické nebo transportní vrstvy. Pro minimalizaci objemu přenášených dat pak může být na úrovni prezentační vrstvy zajišťována i jejich komprimace (compression).