


Model agent/manažer
V minulých dílech jsme se podrobněji zabývali podstatou výpočetního modelu klient/server a jeho možnými podobami. Dnes se podíváme poněkud dopředu, na další směry vývoje, které se v poslední době začínají objevovat - ať již jen v náznacích, nebo již ve formě konkrétních představ a standardů, či dokonce dostupných produktů.
Již minule jsme si naznačili, že původní motivace pro budování „klasických" řešení na bázi výpočetního modelu klient/server - tj. snaha minimalizovat objemy dat přenášených po síti - se s postupem času stává méně a méně imperativní. Na důležitosti naopak začínají nabývat jiná kritéria a omezující podmínky, a do budoucna lze očekávat, že rozhodující faktory budou mít čím dál tím více „logický" charakter, než charakter „fyzický". V tom smyslu, že pořízení dostatečné přenosové kapacity či kapacity výpočetní se stane spíše otázkou ekonomické rozvahy a ekonomické únosnosti, ale nebude to již principiálním technickým problémem. Co naopak bude stále obtížněji řešitelné, a co se tudíž dostane do popředí zájmu, budou „logické" aspekty typu zajištění konzistence a integrity dat, celá oblast interoperability existujících platforem a na nich stojících systémů, a především pak problematika dekompozice řešení, která svou složitostí a komplexností již dnes přerůstají hranici zvládnutelnosti. Právě tento poslední faktor pak zřejmě nejvíce ovlivní budoucí výpočetní modely.
Jak zvládnout rostoucí složitost?
V oblasti vývoje rozsáhlých programových celků (neboli v programování „ve velkém") se již dávno přišlo na to, že řešit velký problém či úkol jako celek je těžší a pracnější, než rozložit jej na více menších a samostatně řešitelných celků. Někdy, při opravdu velkých úkolech, dokonce může být jejich dekompozice a řešení „per partes" jedinou možností, jak se s velikostí a složitostí daných úkolů úspěšně vyrovnat. V konkrétním případě programování to vedlo na vznik různě modulárních řešení, jejichž části (moduly) ale byly povětšinou úzce lokalizovány - po svém naprogramování a odladění byly zase „poskládány" do jednoho většího celku, typicky do jediného výsledného programu, nebo do dvou jeho disjunktních částí (šlo-li například o řešení vycházející z modelu klient/server). Podstatné přitom bylo to, že dekompozice zde byla provedena pro potřeby naprogramování, a nikoli pro potřeby provozování výsledného systému. Do budoucna lze ale očekávat, že vzhledem k náročnosti, složitosti a celkové komplexnosti řešených úkolů bude nutné zavést dekompozici i do vlastního „fungování" výsledných řešení - tedy rozdělit je na více relativně autonomních částí, které budou provozovány samostatně a požadované úkoly a funkce budou plnit ve své vzájemné součinnosti. Nejčastěji přitom půjde o takové části, které mají společný původ, vznikly ze stejného důvodu a pro jeden a tentýž společný účel. Není to ale nezbytnou podmínkou, protože na vzájemné spolupráci se mohou podílet i takové celky, které vznikly nezávisle na sobě, buď pro nějakou jinou konkrétní potřebu, nebo i jako univerzální prvky, vytvořené „do zásoby" pro případ jejich potřeby.
Obecně je právě popsaná myšlenka označována jako „cooperative processing", a její podstatou je právě to, co vystihuje u nás poněkud zprofanovaný pojem „kooperace", neboli spolupráce více složek na společném úkolu. Model klient/server, kterým jsme se až doposud zabývali, je vlastně elementární formou takovéhoto kooperativního způsobu fungování - založený na existenci dvou složek, které byly vytvořeny k naplnění společného cíle, a které si mezi sebou rozdělují tři základní okruhy činností (prezentaci, aplikační logiku a správu dat, viz minule). Do budoucna lze ale očekávat, že „kooperace" bude obecnější, bude se na ní podílet více složek než jen dvě, a také že jejich vzájemná dělba práce bude nejspíše dosti různorodá, stejně tak jako postavení kooperujících složek.
Budoucnost bude distribuovaná!
Podobně jako model klient/server, je i obecnější „cooperative processing" především myšlenkou, resp. představou o rozdělení rolí a dílčích úkolů, a nikoli předpisem pro konkrétní implementaci - i když si v sobě nese určitý rámcový předpoklad o obvyklém způsobu implementace. V roli klienta a serveru proto mohou vůči sobě vystupovat i dvě aplikace, provozované na jednom a témže počítači, ale obvyklým případem bude spíše situace, kdy se obě tyto složky nachází na různých uzlových počítačích sítě. Podobně tomu je i s myšlenkou „cooperative processing". Také zde asi bude v principu možné, aby k obecnější a jemnější dělbě práce docházelo mezi úlohami či aplikacemi v rámci jediného počítače. Typickým však bude spíše případ, kdy jednotlivé složky poběží na různých uzlových počítačích, samozřejmě vzájemně propojených a schopných komunikace. Půjde tedy o takový systém, který je třeba označit přívlastkem „distribuovaný" (distributed).
Symetrické, nebo asymetrické postavení složek?
Jakmile připustíme, aby se na plnění společném úkolu podílelo více různých složek, je vhodné se ptát po jejich postavení a vzájemných vztazích - jsou si všechny složky víceméně rovny, nebo mezi nimi existují takové vztahy, které je nějakým způsobem diferencují? Tedy například vztahy nadřízenosti a podřízenosti, vztahy poskytovatele a „konzumenta" či něco ještě jiného? Možné jsou v zásadě obě varianty (se stejným i nestejným postavením jednotlivých složek), a v praxi nejspíše budou vznikat nejrůznější varianty, patřící do obou táborů. Ukažme si dnes jednu z variant, které se již objevily (a jiné si necháme na příště).
Agent a jeho manažer
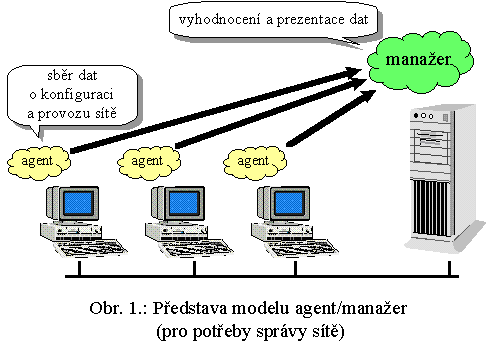 |
Inteligentní agenti
Nesymetrický vztah mezi jedním „manažerem" a jemu podřízenými „agenty", naznačený výše, může mít ještě obecnější povahu. Zatímco v předchozím případě byli agenti fixováni na určitou platformu a byli pro ni „šiti na míru", je možné i takové řešení, v rámci kterého budou „agenti" univerzální, nebudou již vázáni na konkrétní specifickou platformu, a dokonce budou moci i cestovat - tedy vykonat část svých úkolů na jednom místě, pak se přesunout jinam a zde v plnění svých úkolů pokračovat. Takovíto agenti už ale budou muset vykazovat vysokou míru autonomie a vlastní inteligence, a také již nebudou v tak závislém postavení na svém manažeru - jeho role se změní spíše v roli generátora agentů, které je bude vypouštět do sítě za účelem splnění konkrétních úkolů, a současně v roli koordinátora, který bude dohlížet nad činností jednotlivých agentů a zprostředkovávat jejich součinnost.
Pokud vám právě naznačená představa zní jako hudba vzdálené budoucnosti, není to vůbec pravda. Jde o technologie, která existují a jsou dostupné již dnes - nabízí je například firma FTP Software jako tzv. CyberAgent Technology, nebo firma General Magic jako technologii Telescript.