


Model file server / pracovní stanice?
Samostatné a navzájem zcela izolované osobní počítače dokázaly zbavit uživatele nutnosti cokoli sdílet s kýmkoli jiným. Velmi brzy se ale ukázalo, že ani tato situace není zdaleka optimální - že některé věci je naopak rozumné sdílet. Záhy se tak objevila velká poptávka po vhodných mechanismech pro sdílení souborů a pro nejobvyklejších periferií typu tiskáren. Tuto poptávku dokázaly vcelku uspokojivě pokrýt rodící se lokální počítačové sítě. Znamenalo to ale i změnu výpočetního modelu?
Nevýhody plynoucí ze vzájemné izolovanosti samostatných osobních počítačů jsme si zdůrazňili již minule, a proto jen stručně: problém je jednak se správou mnoha samostatných počítačů, které musí mít všechno potřebné „u sebe" (a někdo musí toto „všechno" udržovat, aktualizovat atd.). Druhým základním problémem byla spolupráce uživatelů samostatných počítačů, například jejich přístup do jedné a téže databáze, obecně pak práce nad společnými daty. Mají mít všichni své vlastní repliky? Jak to bude s jejich průběžnými aktualizacemi?
V původním centralizovaném světě, obývaném modelem host/terminál, obdobné problémy sice také vznikaly, ale byly mnohem snáze řešitelné, protože k nim docházelo jen jedenkrát a na jednom místě. Nelze se tedy divit, že lidé brzy pocítili potřebu vzájemně propojit své osobní počítače, a zařídit věci tak, aby alespoň některé soubory mohly být uloženy centrálně a mohly být sdíleny více uživateli.
Na pomoc přichází Ethernet
Prakticky ve stejné době, kdy se na scéně objevují první osobní počítače, rodí se v laboratořích výzkumného střediska PARC firmy Xerox další převratná věc - přenosová technologie, záhy pojmenovaná Ethernet.
Ethernet měl téměř ideální vlastnosti k tomu, aby pokryl vznikající potřebu propojení osobních počítačů. Byl relativně jednoduchý, a nebylo příliš těžké jej implementovat. Měl sice malý dosah (stovky metrů), ale to nijak moc nevadilo, protože měl většinou sloužit k propojení počítačů nacházejících se nepříliš daleko od sebe. Hlavně ale byl dostatečně rychlý - jeho nominální přenosová rychlost 10 megabitů za sekundu umožnila přenášet soubory tak rychle, že již nemusel vznikat markantnější rozdíl mezi přístupem k místním souborům a přístupem ke vzdáleným souborům, nacházejícím se na některém jiném počítači. Právě to byl totiž velmi podstatný moment, umožňující překonat psychologickou bariéru v pohledu uživatelů na sdílené soubory a zařídit věci tak, aby uživatel vlastně ani nemusel tušit že pracuje se vzdáleným souborem.
Vznikají file servery
Potřeba sdílení souborů v prostředí vzájemně propojených osobních počítačů, na „krátkou vzdálenost" (tedy v lokální síti) záhy vyústila ve vznik specializovaných uzlů, plnících roli „centrálních depozitářů souborů". Vžilo se pro ně označení file server, které je i v češtině více vžité, než doslovný překlad „souborový server".
Jak již jeho název naznačuje, je file server serverem, a tudíž poskytovatelem určité služby (zatímco ostatní uzly, které jeho služby využívají, jsou vůči němu v postavení klientů). Obsahem poskytované služby není nic jiného než uchovávání souborů - file server nabízí svým klientům, že pro ně na svých discích uchová jejich soubory. Pro konkrétní naplnění této služby pak od svých klientů přijímá příkazy typu: „zde je obsah souboru X.Y, uchovej si jej u sebe", či „pošli mi obsah souboru XY".
Zajímavá je na celé věci i skutečnost, že klient nemá file serveru co mluvit do toho, jak si on jeho soubory ukládá na svůj disk. Je věcí file serveru, jaké „souborové hospodářství" si zvolí a bude používat. Díky tomu je například možné, aby file server i jeho klient stáli na odlišných platformách - aby například file server byl Unixovým strojem, a soubory si uchovával „Unixovým" způsobem, zatímco jeho klient byl osobním počítačem s MS DOSem.
Původně existovaly ještě také tzv. diskové servery (disk servers), ale ty časem zanikly. Byly charakteristické tím, že na rozdíl od file serverů poskytovaly svou diskovou kapacitu „na stojato": jejich klienti jim posílali požadavky typu „zapiš tato data do sektoru X stopy Y cylindru Z", či „načti mi obsah sektory X stopy Y na cylindru Z". Zde to tedy byl klient, kdo se staral o organizaci souborů na disku, zatímco v případě dnes zcela dominujících file serverů je toto úkolem file serveru.
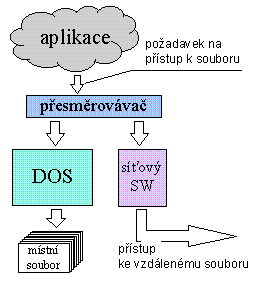
Správný file server není vidět
 |
 |
Výsledným efektem působení přesměrovávače bylo zpřístupnění adresářových stromů file serveru klientům (osobním počítačům, později označovaným i jako pracovní stanice) takovým způsobem, že pro ně se „tvářily" jako skutečně místní zařízení (např. jako místní pevné disky). V praxi se hovoří o tzv. mapování adresářových struktur file serveru na logická zařízení (logické jednotky) klientů, viz obrázek č. 2.
Vzniká nový výpočetní model?
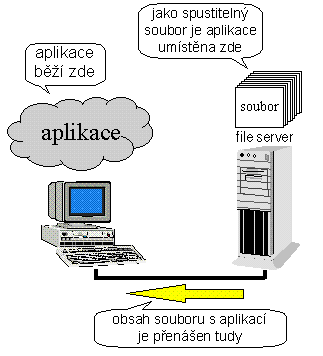 |
V některých situacích ovšem může být výhodné, aby si aplikace existenci sítě uvědomovala. Například tehdy, když může být spuštěno více instancí téže aplikace (přesněji spuštěno více instancí programu, umístěného jako soubor na file serveru). Pak je například vhodné, aby si každá z nich vytvářela své pracovní soubory (potřebuje-li nějaké) jinde než ostatní instance, aby nedocházelo k jejich vzájemnému ovlivňování. Další motivací je pak snaha umožnit více uživatelům práci nad společnými daty, které se nyní již mohou nacházet na jediném společném místě, jako centrálně umístěné soubory na file serveru. Pokud by se totiž různé aplikace (či alespoň různé exempláře jedné a téže aplikace) snažily o současný přístup k jednomu a témuž souboru, nastaly by problémy. Ty se samozřejmě dají řešit, například různými způsoby zamykání celých souborů či jejích částí buď na jakýkoli přístup, nebo jen na zápis apod. Nicméně aplikace, která má tyto mechanismy používat, si existenci síťového prostředí obecně i těchto mechanismů konkrétně musí uvědomovat. Takže správná odpověď na původní otázku je spíše kladná: přeci jen vzniká nový výpočetní model. Nemá však dodnes příliš ustálené jméno, říkejme mu tedy „model file server / pracovní stanice".