


Co jsou a jak fungují kanály?
Vyjdeme-li z terminologie zavedené firmou Pointcast a z filosofie její služby Pointcast Network, pak informace dopravované k uživateli jsou členěny do tzv. kanálů (channels), které se mohou (ale nemusí) dále větvit na další části (dílčí kanály). Tím vzniká celá hierarchická struktura kanálů (která ale zhusta je pouze jednopatrová), a na jejím konci jsou jednotlivé informační položky (anglicky: items), tvořené konkrétními články (nejčastěji v podobě jednotlivých WWW stránek). Konkrétní představu na příkladu dvou tuzemských kanálů ilustrují obrázky, s tím že příslušnou strukturu typicky definuje poskytovatel informací (provozovatel kanálu), ale v zásadě si ji může vytvořit i sám uživatel.
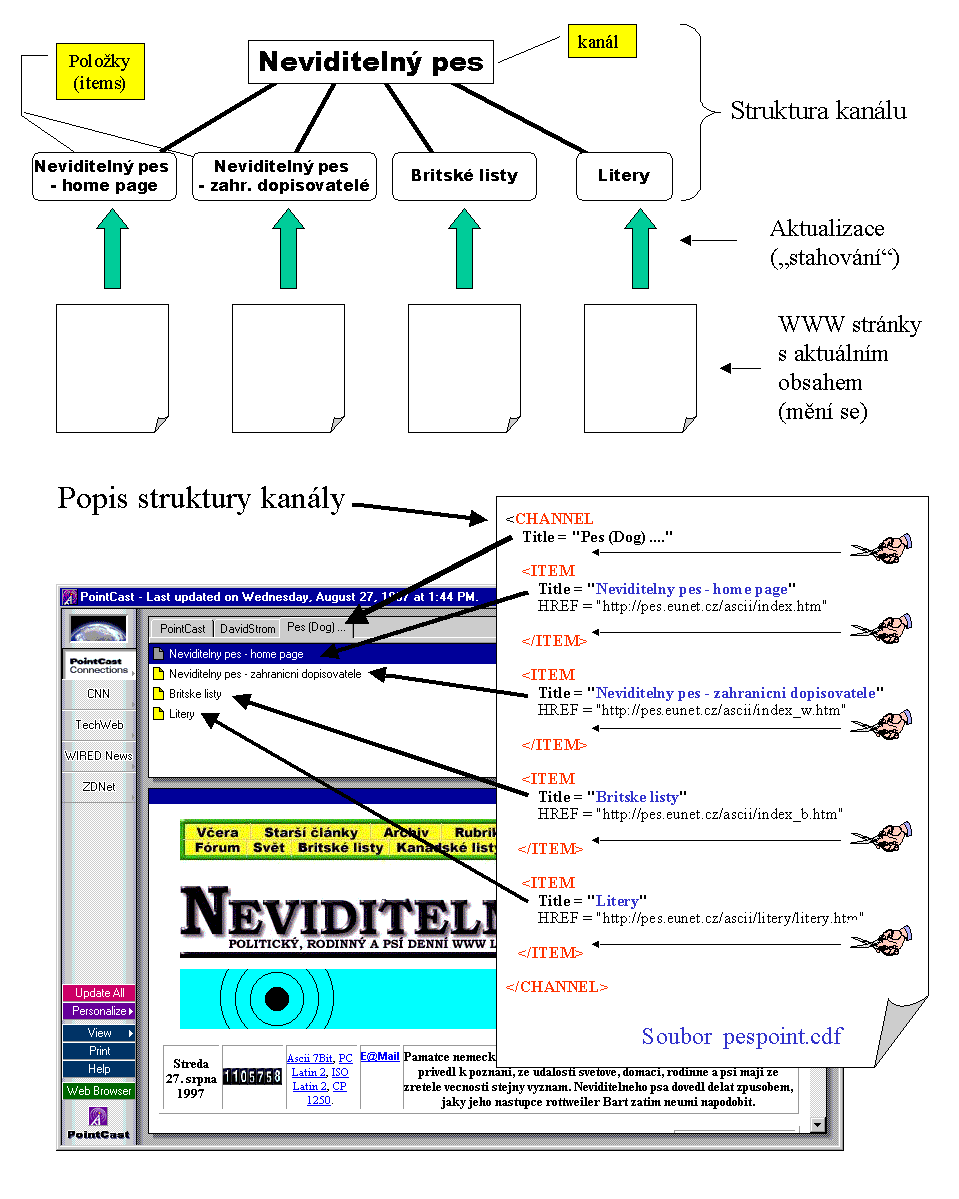 |
Pro jednodušší vyjadřování, a také proto abychom byli v souladu s rodící se terminologií, budeme celé takovéto hierarchické struktury označovat celé jako "kanály" (v singuláru) - takže například kanál Atlas-u, byť obsahující dílčí "podkanály" (např. "Český Internet") budeme stále chápat jako jediný logický kanál.
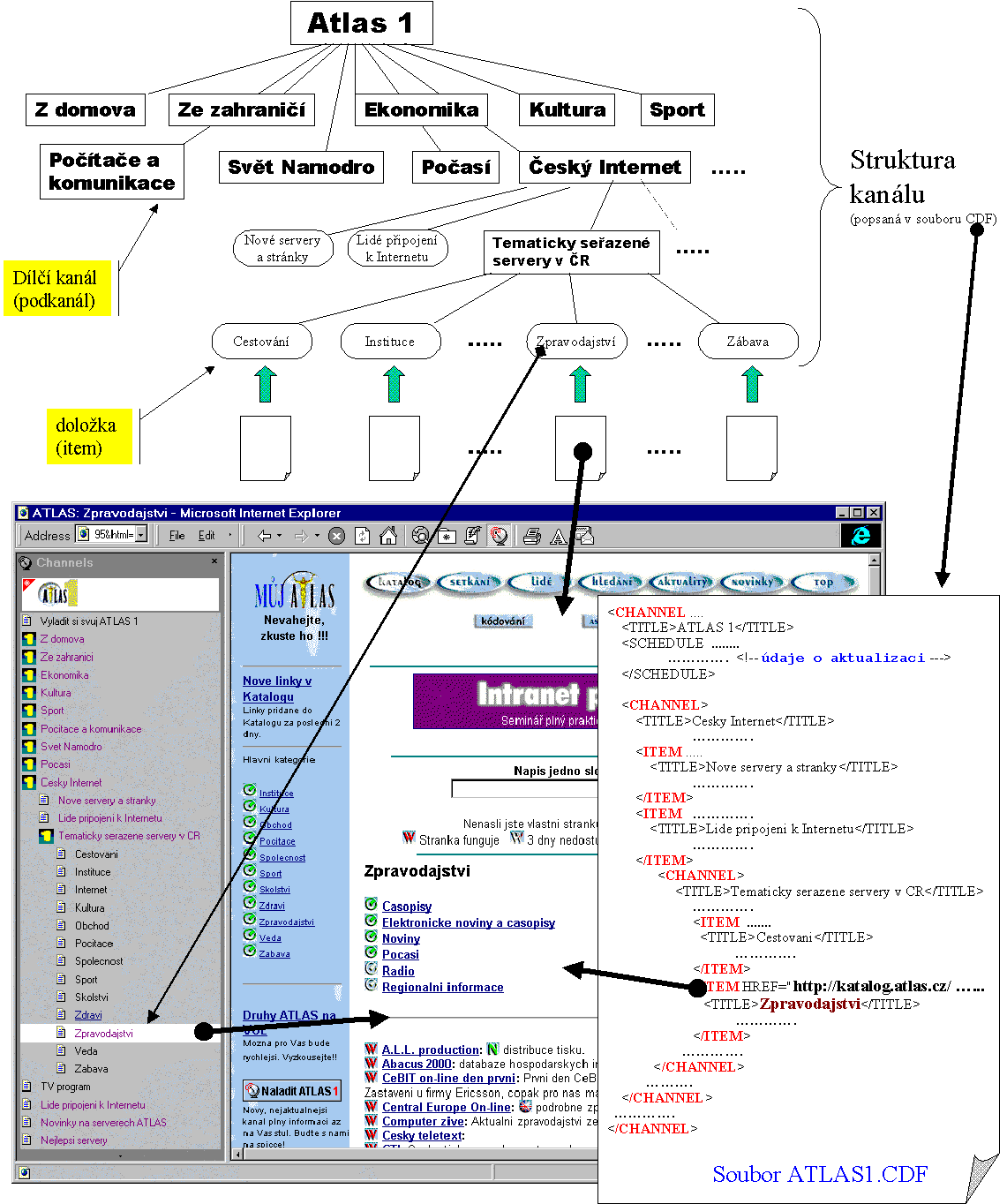 |
Celý mechanismus "push-ování" pak vychází z toho, že pro každý kanál (a obecně i pro jeho jednotlivé složky) je možné vyspecifikovat, kdy a jak často má být jejich informační obsah dopraven k uživateli a zde umístěn (např. na jeho disku, v oblasti fungující jako vyrovnávací paměť). Například zde může být řečeno, že obsah určité stránky má být dopraven k uživateli jednou denně, vždy ráno v 9 hodin, nebo že má být načítán pravidelně každým 6 hodin, nebo naopak že nemá být sám od sebe přenášen vůbec, a vše má být ponecháno až na rozhodnutí uživatele, který musí sám vydat explicitní popud k přenesení článku. Zajímavé přitom je, že ve většině současných implementací je takovýto přenos nového obsahu iniciován a prováděn klientem, resp. programem běžícím na straně uživatele - takže místo operace typu "push" (doslova: tlačení) jde naopak o "pull", neboli o "táhnutí", "stahování". Ale to na principu věci nic nemění (a kromě toho jsou na obzoru i takové přenosové technologie, u kterých je i faktický přenos iniciován zdrojem informací, viz dále).
Jaký je ale celkový efekt toho, že určitý informační obsah, daný strukturou kanálu, je dopravován přímo k uživateli a zde skladován? V odpovědi na tuto otázku je skryt hlavní klíč k pochopení toho, proč jsou dnes služby typu information push tak populární - odstraňují chybující lidský faktor, a nahrazují jej automaticky fungujícími mechanismy, které neznají únavu, nemají další zájmy a povinnosti, a tedy nic co by je odvádělo od plnění toho, co se po nich chce, tedy od pravidelného dopravování čerstvých informací, podle předem daného harmonogramu, uživateli "až pod nos". Pro samotného uživatele je to velmi pohodlné, protože on sám nemusí dělat nic. Může se tak dít dokonce i na pozadí, v době kdy uživatel používá svůj počítač k jiným účelům. Navíc je pamatováno i na uživatele, kteří nemají trvalou konektivitu do Internetu - jejich počítač si v určité době "nacucne" příslušnou dávku čerstvých informací, a uživatel je pak může "konzumovat" později, v době kdy již nemusí vůbec být připojen k Internetu. Právě popsaný způsob práce s informacemi je pro uživatele jistě velmi pohodlný, ale současně je i velmi nebezpečný - může se totiž snadno odchýlit od původního záměru shromažďovat specificky zaměřené informace podle konkrétních požadavků uživatele, a sklouznout zpět k prvotnímu distribučnímu modelu, v rámci kterého jsou uživatelé zaplavováni množstvím informací které vůbec nechtějí. Skutečným klíčem k úspěchu technologií na principu information push tedy bude to, zda poskytovatelé obsahu (autoři kanálů) dokáží citlivě naplnit potřeby svých zákazníků, a nevnucovat jim příliš mnoho takových informací, o jaké zájem nemají. Zde může významně pomoci mnohem větší "granularita" informačních zdrojů, neboli mnohem větší možnost pro uživatele přesně si vyspecifikovat co je zajímá a co nikoli, a tedy výrazně větší individuálnost informačních kanálů. To je samozřejmě provozně i ekonomicky mnohem náročnější. Nelze se proto moc divit, že v současné době je většina nabízených kanálů jen velmi málo individuálních.