


Báječný svět počítačových sítí
Část XVI. : Alternativní výpočetní modely
Výpočetní model klient/server je v prostředí dnešních počítačových sítí stále nejrozšířenější. Ale vedle něj se objevovaly a stále objevují i zajímavé alternativy. Některé z nich zazářily a zase pohasly, jako třeba model Network Centric Computing. Ke svému fungování jej měly využívat tzv. tencí klienti, alias počítače NC (Network Computer). Ty se měly stát protipólem tzv. tlustých klientů, reprezentovaných hlavně klasickými počítači PC (Personál Computer). Nakonec z toho ale nic moc nebylo. To jiné alternativy naopak stále žijí a těší se čím dál tím větší oblibě. Jako třeba model Server-based Computing. Že ho neznáte?Problematika výpočetních modelů, kterou jsme se začali zabývat v minulém dílu tohoto seriálu, se týká toho, jak aplikace fungují, jak jsou řešeny (např. zda jsou monolitické, či zda jsou rozděleny na několik částí či nikoli), kde mají uložena svá data a kde je zpracovávají, či jak komunikují s uživatelem atd. Popisovali jsme si také historický vývoj výpočetních modelů, který vedl až ke vzniku dnes zřejmě nejrozšířenějšího modelu klient/server. Ten je přímo šit na míru distribuovaném prostředí počítačových sítí, protože předpokládá rozdělení aplikace na dvě části - serverovou (server) a klientskou (klienta) - s propojením pomocí vhodné sítě.
Na výpočetním modelu klient/server je dnes postavena i většina aplikací, resp. služeb, fungujících v prostředí Internetu. Třeba když se brouzdáte na vlnách báječného světa World Wide Webu, ani si možná neuvědomujete, že k tomu využíváte klientský program (klienta) v podobě webového prohlížeče (browseru), který si na základě našich pokynů vždy vyžádá požadovanou WWW stránku od konkrétního WWW serveru. Nebo že když čtete či píšete své emaily, používáte k tomu poštovního klienta, zatímco samotný přenos zpráv zajišťuje poštovní server.
Také jsme si ale řekli, že model klient/server má i své nevýhody. Například tu, že pro každou aplikaci, resp. službu, musí uživatel používat jiného klienta (jiný klientský program). Aby jich na svém počítači nemusel mít instalováno příliš mnoho, a s každým se nemusel učit pracovat jeho specifickým způsobem, objevilo se i vylepšení klasického modelu klient/serveru, v podobě 3-úrovňového modelu klient/server.
Naše dnešní povídání, o "alternativních" výpočetních modelech, začneme tím, že ani 3-úrovňový model klient/server není jedinou možností, jak se zbavit přehršle různých klientů na vlastním počítači.
Network Centric Computing
Poměrně radikální alternativou (k nutnosti instalovat si na počítači řadu různých klientů) je zařídit vše tak, aby na počítači nemuselo být dopředu nainstalováno vůbec nic. Tedy ani žádní klienti (klientské programy), ani jiné programy, včetně těch monolitických ("v jednom kuse", resp. nedělených na klientskou a serverovou část). Pokud by pak uživatel takového počítače chtěl něco začít dělat, například psát nějaký text, číst si své emaily či brouzdat se webem, vše potřebné by se na jeho počítač stáhlo ze sítě a zde spustilo. A po použití by se to zase zahodilo, jako nějaký papírový kapesník na jedno použití.
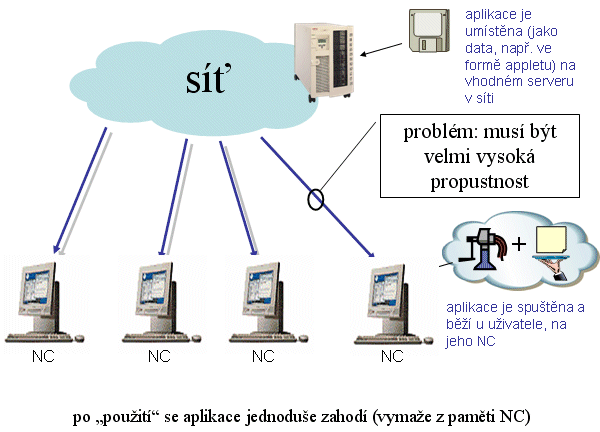 |
Popišme si to celé ještě jednou, tentokráte z jiného pohledu. Jde o řešení, v rámci kterého jsou aplikace umístěny na vhodném serveru, který se nachází někde v síti. Teprve v okamžiku, kdy na uživatelově počítači vznikne potřeba použít nějaký takovýto program, je tento stažen ze sítě (přenesen ze síťového serveru na uživatelův počítač) a zde spuštěn. Vše naznačuje i dnešní první obrázek.
Základem všeho zde tedy je síť (s příslušnými servery), která poskytuje uživatelům vše potřebné, kdykoli si o to řeknou. Snad právě proto se také celému tomuto výpočetnímu modelu říká Network Centric Computing. Tedy něco jako "výpočetní model, jehož středem je síť". Ta je zde skutečně středem všeho, protože s ní stojí a padá možnost smysluplné práce na počítačích uživatelů. Jakmile by síť nefungovala a neposkytovala programy ke stažení a spuštění, uživatelů by jejich počítače byly k ničemu.
Jazyk Java, javovské aplety a javovský virtuální stroj
Stahování programů ze sítě samozřejmě musí probíhat dostatečně rychle, tak aby uživatel nezaznamenal žádné významnější zpoždění od okamžiku, kdy projevil své přání (že chce něco dělat), do okamžiku, kdy je příslušný program stažen ze sítě a spuštěn na jeho počítači. To samozřejmě klade velké nároky na rychlost a propustnost sítě, ze které je program stahován. Ale není to zdaleka jediný požadavek.
Dalším nezbytným požadavkem je to, aby program, stahovaný ze sítě, vůbec byl schopen běžet na počítači, na který je stažen. A to nemusí být pokaždé stejný počítač! Takže by to měl být nějaký takový tvar programu, který je spustitelný a schopný plnohodnotné práce na různých platformách, na kterých může být uživatelům počítač postaven (tedy třeba na MS Windows, na Unixu, Linuxu, na MacOS atd.).
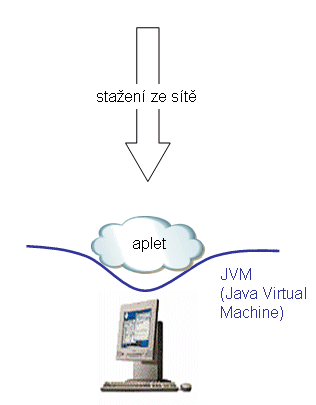
Takovýmto tvarem programu jsou například aplety jazyka Java, což jsou jakési předkompilované (před-přeložené) programy, uzpůsobené k tomu, aby mohly běžet na různých platformách, včetně různých procesorů a operačních systémů. Vždy ale za podmínky, že na příslušné platformě najdou stejné "domovské prostředí", které pro ně představuje tzv. javovský virtuální stroj (JVM, Java Virtual Machine). Ten si můžeme představit jako jakýsi "virtuální počítač v počítači".
 |
Tlustý proti tenkému
Možnost stahovat vše potřebné ze sítě na počítače uživatelů, díky modelu Network Centric Computing, má i některé další významné důsledky. Například tu, že výrazně snižuje náklady na správu a údržbu uživatelských počítačů. Díky celému principu fungování tohoto modelu totiž uživatelské počítače mohou být poměrně jednoduché a "nerozbitné", protože se od nich očekává jen jedna jediná věc: schopnost stáhnout si ze sítě to, co je momentálně potřebné, a pak tomu předat řízení (spustit to a nechat běžet). A po použití (po skončení práce s příslušným programem) to jednoduše zahodit.
To je poměrně zásadní odklon od koncepce, se kterou se setkáváme u běžných pracovních stanic a osobních počítačů. U těch se totiž předpokládá, že na nich budou dopředu instalovány určité programy, tak aby byly pohotově k dispozici, pokud by o ně uživatel projevil zájem. Určitě to dobře znáte ze své praxe: kolik máte na svém počítači nainstalováno nejrůznějších aplikací, které jste už jak dlouho nepoužili (pokud vůbec)? Zcela určitě na vašem počítači jen zabírají místo na disku a další zdroje (třeba i operační paměť, skrze své knihovny).
Můžeme si to představit také tak, že klasický počítač PC je "tlustý" - právě v tom smyslu, že neustále bobtná instalováním dalších a dalších aplikací, které mohou, ale také nemusí být nikdy zapotřebí. Naproti tomu počítač, který si vše potřebné stahuje ze sítě, díky modelu Network Centric Computing, může být "tenký" (ve smyslu: jednoduchý odlehčený). Hovoří se o něm také jako o "tenkém klientovi", ale možná ještě výstižnějším označením je Network Computer, zkratkou NC (neboli: síťový počítač), kvůli vazbě na celý model Network Centric Computing.
NC vs. PC
Síťové počítače, alias počítače NC, jsou často dávány do protikladu k počítačům PC. Stejně tak se hovoří i o tenkých klientech (NC), jako o protipólu k tlustým klientům (PC).
Pravdou je, že ještě před několika lety se tenkým klientům (počítačům NC) přisuzovala velká budoucnost, a to jednak kvůli nižší pořizovací ceně (díky větší jednoduchosti), i kvůli výrazně nižším nákladům na správu a systémovou údržbu. Mohou to totiž být značně "blbovzdorná" zařízení, na kterých uživatel nemá co pokazit. A pokud by snad přeci jen něco pokazil, pak stačí je vypnout a znovu zapnout - a NC si vše potřebné znovu stáhne ze sítě.
Ovšem praxe představy o masovém zavádění počítačů NC nenaplnila. Jednak proto, že cenový rozdíl oproti klasickému PC se v mezičase stal relativně malým, až zanedbatelným. Stejně tak ale asi i proto, že přepsat rychle všechny skutečně používané aplikace do zcela nové podoby (nejspíše do podoby javovských apletů), se ukázalo jako nereálné. A když už se to někde podařilo, tak se zase zjistilo, že úzké hrdlo přeci jen může být v síti a v její omezené propustnosti, kvůli které by se větší aplikace stahovaly neúnosně dlouho.
Například kanadská firma Corel svého času už prakticky dokončila vývoj celého kancelářského balíku (Corel Office for Java) pro počítače NC a model Network Centric Computing. Pak jej ale sama předčasně ukončila. Mimo jiné kvůli tomu, že stahování celého kancelářského balíku, i z dostatečně rychlé sítě, trvalo neúnosně dlouho. Ovšem ani další podobné pokusy (například od firem IBM či Lotus) nebyly o nic úspěšnější.
Renesance modelu host/terminál?
Výpočetní model Network Centric Computing tedy moc úspěšný nebyl. Možná i proto, že poněkud předběhl svou dobu, a přišel příliš brzy se zcela novým konceptem (konceptem programů, stahovaných ze sítě až na základě skutečné potřeby). To další model, který si nyní popíšeme, na to šel úplně jinak. Jde o výpočetní model, který se jakoby "vrací zpět ke kořenům", k již osvědčenému řešení (výpočetnímu modelu) host/terminál, a snaží se jej upravit tak, aby vyhovoval současným potřebám.
Připomeňme si, že model host/terminál předpokládá, že všechny zdroje (programy, data, výpočetní kapacita, periferie atd.) jsou umístěny na jednom centrálním místě, a to na hostitelském počítači (host-u), na kterém také všechny aplikace po svém spuštění běží. Uživatelé pak s těmito aplikace pracují prostřednictvím terminálů, na které jim jsou zasílány výstupy příslušných aplikací, a ze kterých jsou naopak odesílány zpět vstupy od uživatelů (hlavně z klávesnice), určené těmto aplikacím.
Významnou předností modelu host/terminál bylo to, že vše v něm bylo "na jedné hromadě" (na hostitelském počítači), a to velmi výrazně usnadňovalo systémovou správu a údržbu. Kdykoli byl potřeba nějaký zásah, dělal se na jednom místě a pro všechny uživatele současně.
Nevýhodou modelu host/terminál pak bylo to, že svým uživatelům nabízel jen malý komfort, alespoň z dnešního pohledu. Fungoval totiž jen ve znakovém režimu, a nikoli v grafickém, na který jsou dnes uživatelé zvyklí. Důvody k tomu omezení přitom nebyly principiální, ale ryze praktické: pokud by aplikace, běžící na hostitelském počítači, generovaly své výstupy v grafice, pak objemy dat, které by se musely přenést na terminály uživatelů, byly neúnosně velké. Dokonce tak velké, že ani při dnešních propustnostech lokálních sítí by jejich přenos nebyl únosný.
Server-based computing
A jak tedy vypadá moderní alternativa k dřívějšímu modelu host/terminál? Místo zastaralého "hostitelského počítače" (v angličtině "host"), již operuje s modernějším pojmem "server". Beze změny je ale to, že na tomto serveru (již ne "hostitelském počítači") jsou soustředěny všechny zdroje, včetně všech aplikací, a zde také tyto aplikace běží. Proto se také o příslušném serveru hovoří také jako o aplikačním serveru. To proto, že jako svou službu poskytuje možnost provozování (běhu) celých monolitických aplikací.
Ale jak je to s druhou polovinou původního názvu host/terminál, tedy s terminálem, resp. s terminály?
Také ty se s postupem času změnily. Již to nejsou ony historické terminály, většinou tvořené jen monitorem a klávesnicí. Dnes v roli původních terminálů vystupují opravdu nejrůznější zařízení, od osobních počítačů (případně počítačů NC), přes různé tablety, zařízení PDA, až třeba po mobilní telefony. Skrze všechna tato zařízení, mnohdy velmi mobilní, chtějí být uživatelé ve styku se svými úlohami, které běží na aplikačním serveru.
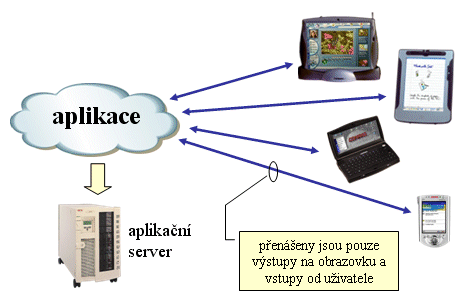 |
Kvůli tomu aplikace, běžící na aplikačním serveru, posílají své výstupy nikoli na klasické terminály, ale právě na takováto zařízení nejrůznějšího provedení. Z nich pak také dostávají od uživatelů pokyny ke svému fungování (vstupy z klávesnice, případně od myši či dotykové obrazovky apod.).
V zásadě ale stále platí, že i tato novodobá zařízení vystupují v roli terminálů - a to vůči aplikacím, běžícím na aplikačním serveru. Z tohoto důvodu se lze setkat i s tím, že místo o aplikačním serveru se hovoří o terminálovém serveru (například v rámci terminologie, používané společností Microsoft).
Ať už ale serveru, na kterém aplikace běží, budeme říkat aplikační či terminálový, podstatný je celý popisovaný výpočetní model. A tomu se říká Server-based Computing, což by se dalo volně přeložit jako "výpočetní model, založený na serverech".
Jak na grafiku?
V čem se ale novodobý model Server-based Computing liší od starého modelu host/terminál?
Už jsme si naznačili, že hlavně v grafice, resp. v možností pracovat na koncovém zařízení s grafickém režimu, s grafickým uživatelským rozhraním. Jenže jak se toto slučuje s předchozí poznámkou, že pokud by aplikace generovaly své výstupy v grafice, objem grafických dat by byl tak velký, že by zahltil i dnešní, jinak dosti propustné sítě?
Po pravdě: moc se to neslučuje. Objemy grafických dat jsou zkrátka stále moc velké, a navíc rychle rostou s vyšším rozlišením a barevnou hloubkou grafického uživatelského rozhraní. Takže jak z toho ven?
Klíčem k úspěchu je negenerovat ony obrovské objemy grafických dat na aplikačním (terminálovém) serveru) ale až na koncovém zařízení (terminálu), kde už jejich velký objem nevadí. Jenže jak to udělat?
Princip je poměrně jednoduchý, a sází na jeden zajímavý trik: aplikace, běžící na aplikačním (terminálovém) serveru, negenerují své grafické výstupy samy, ale využívají k tomu služeb grafického subsystému místního operačního systému. Třeba když potřebují někde otevřít nějaké okénko, zadají tomuto grafickému subsystému příkaz ve stylu "otevři okno, na pozici XY, velikosti Z, v barvě B, s pozadím P" atd. No a teprve příslušný grafický subsystém operačního systému generuje vlastní grafická data, která v rastru obrazovky znázorní příslušné okno.
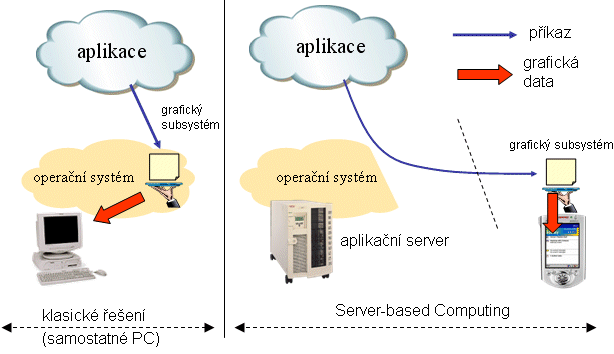 |
Podstatou celého triku je pak přestěhování příslušného grafického subsystému z aplikačního serveru na koncové zařízení, používané uživatelem. Mezi aplikačním serverem a tímto zařízením se pak budou přenášet jen ony příkazy ve stylu "otevři okno …", které mohou být opravdu velmi malé (co do objemu dat, nutných pro vyjádření takovéhoto příkazu). No a vlastní grafické data, třeba i "hodně velká", už jsou generována na koncovém zařízení, nemusí se nikam přenášet, a mohou se hned zobrazit.
Pro fungování takovéhoto řešení může v praxi stačit opravdu minimální přenosová kapacita mezi aplikačním serverem a koncovým zařízením. Například pro provozování kancelářského balíku, jako je MS Word, stačí k běžné práci i 9,6 kbit/s (na jednoho uživatele).
Panning
Právě popsaný model Server-based Computing skutečně dává uživatelům možnost pracovat na dálku s aplikacemi, které ve skutečnosti běží "někde daleko", na vhodném aplikačním serveru. Třeba na aplikačním serveru, který je umístěn ve firmě, zatímco uživatel se právě nachází se svým notebookem, PDA či mobilem někde na druhé straně zeměkoule. Ale ani to mu nebrání, aby na dálku pracoval se všemi aplikacemi, které jsou dostupné ve formě.
Jenže: jak je to se zobrazovacími schopnostmi koncových zařízení (terminálů), které se mohou opravdu výrazně odlišovat? Třeba na displeji PDA či dokonce mobilního telefonu toho lze zobrazit podstatně méně než třeba na displeji notebooku. U původního modelu host/terminál se aplikace ještě snažily samy přizpůsobit možnostem zobrazení na různých terminálech, které se ovšem nelišily až tak zásadně. Jenže zde už to možné není, protože rozdíly jsou opravdu příliš velké.
Proto se u zařízení s malými displeji pracuje s virtuální zobrazovací plochou (tzv. virtuálním desktopem), ze které se do reálného displeje promítá vždy jen část. Aplikace pak přizpůsobuje své výstupy "rozměrům" virtuální zobrazovací plochy, a nemusí se již starat o to, jak velká (či spíše malá) část z této plochy je momentálně viditelná pro koncového uživatele.
Koncový uživatel si přitom může představovat, že displej jeho zařízení, třeba i velmi malý, je jen jakýmsi průzorem do této virtuální plochy, do které mu aplikace promítá své výstupy. A tímto průzorem může podle libosti hýbat, tak aby se podíval na to, co ho právě zajímá. Říká se tomu obvykle panning.
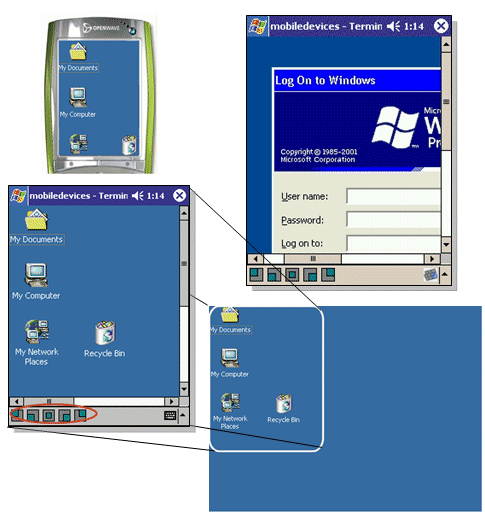 |
Pravda, takovéto "koukání malým průzorem na velkou plochu" rozhodně není ideální, a nedokáže plnohodnotně nahradit zobrazení na dostatečně velkém displeji. Jenže když jiná možnost právě není po ruce ….
Konkrétní příklady
Konkrétních komerčních řešení, fungujících na bází právě popsaného modelu Server-based Computing, je na trhu více. Asi nejznámější je ale to, se kterým přišla firma Citrix, pod jmény MetaFrame a WinFrame (a využívající protokol ICA pro komunikaci mezi aplikačním serverem a koncovým zařízením v roli terminálu). Po určitém váhání přišel s vlastním řešením také Microsoft, pod názvem MS Terminal Server.
Snad nejstarší je ale řešení, vycházející z Unixu, s názvem X Window (pozor, bez "s" na konci). Jeho filosofie je ale v jednom ohledu specifická a zajímavá natolik, že si zaslouží podrobnější zmínku.
Systém X Window se sám o sobě chová jako aplikace, fungující na modelu klient/Server. Jenže co je server, a co klient, a jaké služby nabízí?
Server systému X Window poskytuje službu, spočívající v grafické vizualizaci. Tedy v zobrazování (vykreslování) v grafickém režimu. Lze si jej tedy představit i jako onen "grafický subsystém", který se přestěhoval z aplikačního serveru na koncové zařízení (terminál). A to platí i pro systém X Window: jeho server se nachází na koncovém zařízení (terminálu), protože své "vykreslování" musí provádět právě zde. Naopak jeho klient je umístěn na aplikačním serveru - a tím , kdo jej využívá, je samotná aplikace, provozovaná koncovým uživatelem. Kdykoli tato aplikace potřebuje něco zobrazit svému uživateli, požádá o to klienta systému X Windows. Ten pak předá příslušný požadavek až na koncové zařízení, svému serveru, a ten již zajistí potřebné vykreslení (zobrazení).
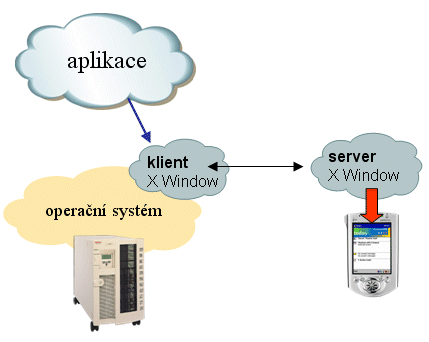 |
Když si to ale vše představíme, podle dnešního posledního obrázku, je umístění klienta a serveru systému X Window jakoby přesně obrácené, oproti běžným zvyklostem: klient je tam, kde bychom očekávali server, a server zase tam, kde bychom intuitivně očekávali naopak klienta. Ale ono je to vlastně dáno tím, jakou službu server systému X Window poskytuje.