


Klient/server na různé způsoby
Výpočetní model klient/server je vhodné chápat především jako dělbu práce mezi dvěma složkami, serverem a jeho klientem. V dnešní době, plné různorodých aplikací, přitom mají obě složky velmi mnoho prostoru pro to, jak konkrétně si mezi sebou rozdělit jednotlivé úkoly. V důsledku toho je pak možné se setkat s více různými variantami modelu klient/server, které se liší právě v tom, kolik toho nese na svých bedrech každá z obou složek. A kromě toho - musí se vždy jednat právě a pouze o dvě složky?
Až doposud jsme za hlavní motivaci celého modelu klient/server považovali snahu minimalizovat objem dat, přenášených po síti mezi klientem a serverem. Imperativnost tohoto kritéria se ale v čase může měnit, zejména v důsledku stále větší dostupnosti přenosových kapacit, a ke slovu se mohou významnějším způsobem dostávat i další kritéria a motivace. Například různá implementační hlediska, související s tím jak obtížné je prakticky implementovat tu kterou složku. Vždyť pořídit si výkonnější hardware či propustnější přenosové cesty je dnes do značné míry již jen otázkou dostatku peněz, zatímco zajištění všeho potřebného pro vývoj i následný provoz aplikací může být mnohem náročnější - ať již jde o potřebný know-how, vhodné vývojové nástroje, personální zajištění i schopnost vše „ukočírovat". No a to samozřejmě také musí ovlivnit konkrétní formu dělby práce mezi servery a jejich klienty.
Tři druhy činností
Výpočetní model klient/server je dnes nejčastěji využíván aplikacemi, které spadají do široké a velmi vágně definované škatulky „Informačních systémů". Představit si pod tím můžeme například aplikace pro podporu nejrůznějších agend všelijakých firem, institucí a dalších orgánů - od účetnictví, skladového hospodářství, až třeba po systémy na podporu rozhodování. Všechny takovéto aplikace přitom mají některé společné rysy. Například se v nich vždy vyskytují nějaká základní data, která musí být vhodným způsobem uskladněna, a současně k nim musí být zajištěn takový přístup, jaký vyhovuje povaze a charakteru samotné aplikace. Další nezbytností je pak nějaká forma komunikace s uživatelem, spočívající jednak ve sběru dotazů a jiných příkazů a povelů od uživatele směrem k aplikaci, a na druhé straně pak i nezbytné zobrazování (či honosněji prezentaci) získaných výsledků. No a pak tu musí být ještě třetí část, která zajišťuje všechno to co je pro danou aplikaci specifické a konkrétní, neboli realizuje vlastní logiku celé aplikace. Například půjde-li o účetnictví, jsou právě zde implementována všechna pravidla, způsobující správné promítnutí jedné účetní operace do všech účtů, podúčtů, knih, listy apod., kterých se to týká.
Zmíněné tři druhy činností, které jsme si právě vymezili, jsou v různých odborných pramenech označovány různě. Naznačme si zde alespoň jednu terminologii, zavedenou prestižní konzultační firmou The Gartner Group:
- Presentation (uživatelské rozhraní a komunikace s uživatelem, neboli prezentační činnosti)
- Application Function (vlastní logika aplikace, tj. aplikační činnosti)
- Data Management (správa dat)
Pět druhů dělby práce
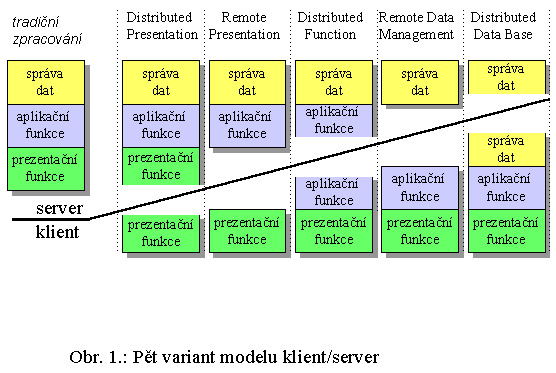 |
- Distributed Presentation: zde jsou prezentační činnosti rozděleny mezi klienta a server (který navíc sám vykonává i všechny zbývající činnosti). Na straně serveru se nejčastěji jedná o generování výstupů ve znakovém režimu do textového okna, které ale ve skutečnosti není nikde zobrazováno. Jeho obsah je místo toho přenášen klientovi, a teprve ten jej zobrazuje uživateli (obvykle již v grafickém režimu emulujícím znakový režim textového okna). Analogicky pak pro obrácený směr, týkající se vstupů od uživatele. Hlavní výhodou tohoto řešení, které se asi nejvíce blíží modelu host/terminál, je skutečnost že serverová část aplikace může používat standardní systémové prostředky pro zobrazování na znakových výstupních zařízeních.
- Remote Presentation: v této variantě jsou veškeré prezentační funkce ponechány na klientovi, zatímco veškeré aplikační funkce a funkce spojené se správou dat zajišťuje server.
- Distributed Function: v této variantě jsou všechny prezentační funkce na klientovi, veškerá správa dat na serveru, a o aplikační funkce se obě složky dělí. Některé činnosti, související s vlastní "„logikou"" aplikace, tedy zajišťuje sám klient, zatímco zbývající obstarává server.
- Remote Data Management: tato varianta předpokládá, že veškeré prezentační i aplikační činnosti zajišťuje klient, zatímco server se věnuje pouze správě dat.
- Distributed Data Base: v rámci této varianty zajišťuje většinu činností klient - veškeré prezentační činnosti, veškeré aplikační činnosti, zatímco o udržování a správu dat se dělí se serverem. Jak již název této varianty napovídá, je tato varianta určena zejména pro podporu distribuovaných databází.
Dvou, nebo tříúrovňová architektura?
Základní premisou, kterou jsme až doposud u celého modelu klient/server předpokládali, je dělba práce mezi dva disjunktní subjekty- server a klienta. Jak se ale tato dvousložkovost slučuje s tím, že většina aplikací které z tohoto modelu vychází musí zajistit tři hlavní okruhy činností? Nebylo by přirozenějším řešení použít složky tři? Pak by rozdělení "kompetencí"" mezi ně mohlo být velmi jednoduché a přirozené, a nemuselo by vést k někdy poněkud krkolomným způsobům rozdělováním tří věcí mezi dva subjekty. Nebylo by tedy koncepčnějším řešení zavést tříúrovňovou architekturu klient/server, místo stávající dvouúrovňové?
Pravdou je, že se tak dnes mnohdy již děje, především u rozsáhlejších a náročnějších aplikací povahy velkých informačních systémů. Dochází zde totiž stále více k osamostatňování databází a systémů řízení bází dat a k jejich přesunu „na pozadí" - neboli na samostatné počítače, které jsou optimalizovány pro provozování různých „databázových strojů", nebo dokonce k jejich distribuování na několik uzlů, v rámci distribuovaných databází. Výhodou je pak i skutečnost, že aplikační činnosti (ve smyslu výše uvedené tříúrovňové klasifikace) mohou být stále méně závislé na konkrétním databázovém stroji, díky pokrokům ve standardizaci způsobů komunikace s databázemi (například díky jazyku SQL).
 |