


Filosofie TCP/IP
Tento článek vyšel v počítačových novinách Computerworld č. 11/95, v rámci tzv. tématu týdne, jako součást série článků věnovaných problematice Internetu.
Díváme-li se na Internet jako na soustavu vzájemně propojených sítí, pak jejich hlavním společným rysem je používání protokolů TCP/IP. Jaká je ale filosofie těchto protokolů, na jakých myšlenkách jsou založeny a jak vlastně fungují?
Lidé, kteří navrhovali protokoly TCP/IP, museli již na začátku své práce učinit mnoho koncepčních rozhodnutí, jejichž důsledky se v plné míře projevují dodnes. Mnohá z těchto rozhodnutí přitom byla diametrálně odlišná od těch, která ve stejném kontextu přijali tvůrci referenčního modelu ISO/OSI - což následně významným způsobem ovlivnilo i "budoucnost" příslušných protokolů. Můžeme-li přijatá rozhodnutí hodnotit s dnešním odstupem cca 15 let, pak zkušenosti dávají celkem jednoznačně za pravdu autorům protokolů TCP/IP. S jedinou výhradou - že nedokázali správně docenit míru svého úspěchu. Tedy že nepočítali s tím, že protokoly TCP/IP bude chtít používat takové obrovské množství sítí, kterým bude třeba přidělit jednoznačné adresy. Mechanismus adresování, který autoři protokolů TCP/IP vymysleli, totiž není dostatečně "nafukovací", a při dnešních obrovských rozměrech Internetu začíná být úzkým místem. Ale k tomu se dostaneme v následujícím článku.
Jednotná poklička nad přenosovou částí sítě
Jak již víme z předchozího článku ("Vzdušné zámky, nebo postupná přístavba?"), autoři protokolů TCP/IP se vcelku pochopitelně rozhodli pro vrstvový model, a tedy pro rozdělení síťových funkcí do hierarchicky uspořádaných vrstev. Konkrétně do čtyř vrstev, z nichž ale tu nejnižší - vrstvu síťového rozhraní (Network Interface Layer) - zcela záměrně nenaplnili s poukazem na to, že v rámci ní mají být použity takové technologie, jaké jsou k dispozici. Jak tomu správně rozumět?
Úkolem vrstvy síťového rozhraní je zajistit přenos bloků dat (většinou označovaných jako rámce, angl. frames) mezi sousedními počítači - tedy mezi dvěma počítači, které spolu mají přímé spojení. Nikoli již takový přenos, který musí přecházet přes nějakou "přestupní stanici", což má na starosti až bezprostředně vyšší vrstva. V prostředí lokálních počítačových sítí (sítí LAN) do vrstvy síťového rozhraní spadají například technologie Ethernet, Token Ring nebo ARCnet, FDDI, 100 VG AnyLAN, a do budoucna sem zřejmě bude stále více pronikat i technologie ATM (Asynchronous Transfer Mode). Skutečnost, že protokoly TCP/IP vrstvu síťového rozhraní nijak nepokrývají znamená, že se nesnaží předepisovat použití žádné konkrétní přenosové technologie, natož pak nějaké své vlastní. O co se naopak snaží, je efektivně využít to, co již na této úrovni existuje a osvědčilo se.
Otázkou ovšem je, jakým způsobem mají protokoly TCP/IP využívat přenosové mechanismy na úrovni vrstvy síťového rozhraní. Jednotlivé technologie, které na této úrovni připadají v úvahu, se totiž mohou i dosti výrazně lišit. Například v tom, jaký formát adres používají, jak velké bloky (rámce) dokáží přenášet najednou, zda umožňují přenos od jednoho zdroje k více příjemcům, zda přenos funguje na spojovaném či nespojovaném principu, neboli zda před každým přenosem dat předpokládá nejprve navázání spojení, či nikoli. Zdaleka nejvýznamnějším rozdílem je pak relativní spolehlivost přenosových cest, která bývá diametrálně odlišná u lokálních sítí a u sítí rozlehlých. Celá záležitost pak nabyla ještě více na významu v okamžiku, kdy si autoři protokolů TCP/IP sami předsevzali, že budou zcela programově vycházet vstříc možnosti vzájemného propojování i dosti různorodých sítí, s odlišnými přenosovými technologiemi.
Na výběr byly dvě varianty - buďto zakrýt veškeré odlišnosti jednotlivých dílčích sítí, nebo je naopak nezakrývat. Nakonec se autoři rozhodli pro první variantu, neboli pro překrytí všech přenosových technologií a vlastností použitých přenosových cest jednotnou "pokličkou", která zcela záměrně zahladí veškerá specifika a případné odlišnosti jednotlivých dílčích sítí, a vyšším vrstvám bude předkládat jednotnou vizi přenosové části sítě jako zcela homogenní soustavy vzájemně propojených dílčích sítí. To na jedné straně výrazně zjednodušilo návrh konkrétních protokolů pro tyto vyšší vrstvy, ale na druhé straně se jednotná "poklička" zcela zákonitě stala zdrojem určité neefektivnosti.
Jakou pokličku zvolit?
Jakmile se autoři protokolů TCP/IP rozhodli pro variantu jednotné "pokličky", museli také zvolit její konkrétní povahu - neboli rozhodnout, jak bude vypadat jednotný obraz přenosové části sítě, který bude tato poklička vytvářet a předkládat bezprostředně vyšším vrstvám. Bude zajišťovat spolehlivý způsob přenosu, nebo pouze přenos nespolehlivý? Nebo bude nabízet oba současně, a vyšší vrstvy si budou moci vybrat? Bude fungovat spojovaným způsobem, a bude tedy před každým přenosem navazovat spojení mezi příjemcem a odesilatelem? Nebo bude fungovat nespojovaně, tj. nebude před každým přenosem navazovat spojení, a místo toho bude každý jednotlivý blok dat přenášet samostatně a "na blint", v dobré víře, že jeho adresát existuje a bude ochoten jej přijmout? Kromě toho bylo třeba učinit i celou řadu dalších rozhodnutí - například to, jak má vypadat jednotný způsob adresování, tak aby bylo možné převádět jednotné adresy na konkrétní formáty, specifické pro konkrétní použitou přenosovou technologii.
Autoři protokolů TCP/IP se nakonec rozhodli pro takový způsob fungování jednotné "pokličky", který bude poskytovat pouze tzv. nespolehlivý přenos. Tomu je třeba rozumět tak, že přenosové mechanismy sice budou usilovat o bezchybný přenos, ale jakmile v nějakém konkrétním případě zjistí že se to nepodařilo, nebudou se samy starat o nápravu. Místo toho budou předpokládat, že o nápravu se postará někdo jiný - konkrétně protokoly vyšších vrstev.
Zajímavé je, že autoři protokolů ISO/OSI při obdobném rozhodování zvolili variantu přesně opačnou: došli k závěru, že bude výhodnější, když se o nápravu chyb při přenosu postará již ta vrstva, na které k chybě došlo, resp. která chybu detekovala. Problém je ovšem v tom, že ošetření chyb a zajištění spolehlivosti přenosu je vždy spojeno s určitou režií, připadající zejména na opakování přenosu těch dat, které se předtím přenesly chybně. Podle představy autorů ISO/OSI si spolehlivost zajišťuje každá vrstva znovu, a příslušná režie se tudíž násobí n-krát. Naopak v případě protokolů TCP/IP se spolehlivost zajišťuje jen na úrovni jedné (vyšší) vrstvy, a odpovídající režie se tedy uplatňuje jen 1-krát. Navíc pouze v případě, kdy je spolehlivost skutečně požadována - což nemusí být vždy a za všech okolností, jak později uvidíme. Díky tomu dokáže řešení, zvolené v případě TCP/IP, efektivněji využívat přenosových schopností té přenosové technologie, která je k dispozici.
Pokud jde o rozhodnutí, zda před každým přenosem má být navazováno spojení mezi příjemcem a odesilatelem, i zde se představy tvůrců TCP/IP a ISO/OSI rozešly opačným směrem. Lze to vysvětlit také tím, že autoři protokolů ISO/OSI měli blízko ke spojům a telekomunikacím, které fungují na spojovaném principu (tj. na principu navazování spojení před případným přenosem), a rozhodli se pro stejné řešení i pro potřeby datových přenosů. Naproti tomu tvůrci protokolů TCP/IP došli k závěru, že alespoň na úrovni jednotné "pokličky" je výhodnější nespojovaný charakter přenosu, nepočítající s žádným navazováním spojení. Ten se totiž dokáže mnohem snáze adaptovat na případné dynamické změny v topologii sítě.
Protokol IP
Praktickou realizací výše uvedených myšlenek a rozhodnutí, tedy realizací jednotné "pokličky", byla pověřena vrstva, označovaná jako vrstva síťová (Network Layer). Mnohdy je ale tato vrstva označována spíše jako IP vrstva (IP Layer, resp. Internet Protocol Layer), podle protokolu IP, který je nejvýznamnějším "obyvatelem" této vrstvy. Je to právě protokol IP, který "drží pohromadě" jednotlivé dílčí sítě, a spojuje je do jediné soustavy vzájemně propojených sítí - čemuž se v angličtině říká příznačně internetwork, či zkráceně internet (odsud také pojmenování protokolu). Nutno ovšem zdůraznit, že internet (psáno s malým "i") je jakoukoli soustavou vzájemně propojených sítí, zatímco Internet (s velkým I) je jednou konkrétní soustavou vzájemně propojených sítí, která již nepotřebuje dalších rozlišujících přívlastků.
Konkrétním úkolem protokolu IP je přenos bloků dat, na úrovni síťové vrstvy označovaných již jako pakety (packets). Protokol IP to dělá tak, že zajišťuje nespolehlivý přenos (ve výše uvedeném smyslu) a pracuje na nespojovaném principu - v této souvislosti se také říká, že poskytuje tzv. datagramovou službu. Dalším významným úkolem protokolu IP je zajišťovat jednotný způsob adresování jednotlivých uzlů i celých sítí, prostřednictvím tzv. IP adres (podrobněji viz následující článek).
Praktickou náplní práce protokolu IP je doručování přenášených dat (paketů) od jejich odesilatele až k jejich koncovému adresátovi - i kdyby to mělo znamenat jejich postupný "přestup" přes případné mezilehlé uzly. Jak tomuto správně rozumět?
V předcházejícím odstavci jsme si řekli, že přenosová technologie na bezprostředně nižší vrstvě (vrstvě síťového rozhraní) dokáže přenášet data jen mezi dvěma počítači, které spolu mají přímé spojení. Je to dáno mj. i tím, že tato vrstva (vrstva síťového rozhraní) nemá žádné informace o skutečné topologii dané sítě a celé soustavy dalších sítí, se kterými může být daná síť propojena. Ostatně, ani by nebylo rozumné jí takovou informaci vnucovat, protože při vzájemném propojení dílčích sítí s různými přenosovými technologiemi (např. při vzájemném propojení Ethernetovských sítí se sítěmi Token Ring, s rozlehlými sítěmi atd.) by docházelo k míchání různých způsobů adresování, různých principů a mechanismů přenosu, různých pohledů na topologii sítě atd. Proto je vhodné poskytnout informaci o skutečné topologii celé soustavy vzájemně propojených sítí až zmíněné "pokličce", která vytváří jednotný pohled na všechny dílčí sítě. Teprve od této pokličky (přesněji od protokolu IP) pak má smysl požadovat, aby dokázala najít cestu mezi kterýmikoli dvěma uzly, i když spolu nemají přímé spojení.
Protokol IP tedy musí mít k dispozici dostatečnou informaci o skutečné topologii dané sítě i všech ostatních sítí, se kterými je daná síť spojena. Když pak má zajistit přenos nějakého konkrétního paketu k určitému adresátovi, musí učinit důležité rozhodnutí - není-li koncový adresát v přímém dosahu (v dosahu přímého spojení z odesílajícím uzlem), pak ze všech přímo dosažitelných uzlů musí protokol IP zvolit takový, který by mohl nejlépe posloužit jako přestupní uzel, přes který by bylo možné příslušný paket doručit. Takovýto přestupní uzel samozřejmě nemusí být jen jeden, protože cesta ke koncovému adresátovi může vést postupně přes několik přestupních uzlů.
Rozhodování o cestách, po kterých mají být pakety přenášeny, se označuje jako tzv. směrování (anglicky: routing). Vzhledem k tomu, že protokol IP zajišťuje přenos paketů na nespojovaném (connectionless) principu, směruje každý paket v každém přestupním uzly vždy znovu a samostatně - tj. v každém uzlu se pro každý paket vždy znovu rozhoduje, kterým směrem jej má odeslat dál. Díky tomu se pak protokol IP dokáže snadno vyrovnat s dynamickými změnami topologie sítí - například s tím, že určitý spoj vypadne či stane se z jiného důvodu neprůchodným. Protokol IP pak jednoduše posílá další pakety jinou cestou.
Další protokoly síťové vrstvy
Zajímavou otázkou je to, jakým způsobem protokol IP získává potřebné informace o skutečné topologii sítě. Není jistě těžké nahlédnou, že má-li průběžně reagovat na změny v této topologii, potřebuje nějaký mechanismus, který by jej dokázal průběžně informovat o případných změnách. Tímto mechanismem je nejčastěji další protokol, fungující na úrovni síťové vrstvy, a to protokol RIP (Routing Information Protocol). Není ovšem zdaleka jediným existujícím protokolem pro šíření směrovacích informací, a dokonce ani protokolem nejefektivnějších. V dnešní době je naopak považován za nevýhodný, a je postupně nahrazován jinými protokoly, které ke své činnosti vyžadují mnohem menší režii než protokol RIP. Je ovšem možné i takové řešení, kdy se protokolu IP předem předepíší potřebné pokyny pro směrování a údaje o existujících spojeních, a tyto informace pak zůstávají statické a nejsou aktualizovány.
Bylo by také chybou představovat si, že protokol IP nějaká data skutečně (tj. "fyzicky") přenáší. Skutečnost je taková, že jakmile v rámci určitého (odesílajícího) uzlu učiní protokol IP potřebné rozhodnutí o směru, kterým má být paket vyslán, předá jej bezprostředně nižší vrstvě (vrstvě síťového rozhraní) k vlastnímu odeslání. Teprve tato vrstva pak zabezpečí přenos paketu ("zabaleného" do přenosového rámce) takovým způsobem, pro jaký je uzpůsobena. Konečný cíl přenášeného paketu tuto vrstvu vůbec nezajímá - na druhé straně přímého spoje je rámec přijat, je vybalen v něm obsažený paket, a ten je předán zdejšímu protokolu IP. Teprve ten pak znovu rozhoduje o tom, kudy dál má být paket odeslán, aby se nakonec dostal ke svému skutečnému adresátovi.
Celá věc má ale jeden malý technický háček: protokol IP se při svém rozhodování o volbě dalšího směru přenosu (při tzv. směrování) rozhoduje podle jednotných adres, tzv. IP adres. Dojde-li však k závěru, že určitý paket má být odeslán např. uzlu s IP adresou X.Y.Z.W, nemůže se jednoduše obrátit na vrstvu síťového rozhraní s požadavkem "odešli tento paket uzlu X.Y.Z.W.". Problém je v tom, že vrstva síťového rozhraní jednotným IP adresám nerozumí. Rozumí pouze takovým adresám, s jakými pracuje konkrétní přenosový mechanismus, použitý na úrovni této vrstvy - v případě Ethernetových sítí jde o 48-bitové Ethernetové adresy, v případě ARCnetu o 8-bitové ARCnetové adresy apod.
Protokol IP tedy musí být schopen převádět tzv. IP adresy (které jsou ve své podstatě pouhou abstrakcí) na různé druhy konkrétních fyzických adres. Opět je v principu možné poskytnout mu předem vyplněnou "převodní tabulku", kterou pak bude používat. V praxi se ale častěji používá jiné řešení, které umožňuje převádět jednotlivé druhy adres mezi sebou dynamickým způsobem.
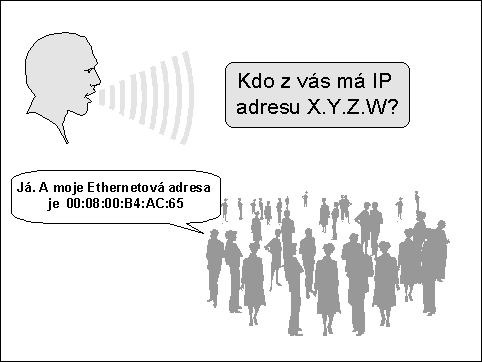
Součástí rodiny protokolů TCP/IP je také protokol ARP (Address Resolution Protocol), který umožňuje převádět IP adresy na adresy fyzické. Při jistém zjednodušení si můžeme představit, že se vždy obrátí na všechny uzly ve svém dosahu s dotazem: "kdo z vás má IP adresu X.Y.Z.W?". Uzel, kterého se to týká, by na takovouto výzvu měl reagovat, a v rámci odpovědi sdělit tazateli svou fyzickou adresu. Vše je přitom založeno na možnosti oslovit všechny uzly současně (v rámci tzv. všesměrového vysílání, angl. broadcasting), prostřednictvím jedné speciální fyzické adresy (která je předem známa).
Náš výčet protokolů, které jsou součástí rodiny protokolů TCP/IP a patří do síťové vrstvy, však u protokolů IP a ARP ještě zdaleka nekončí. Do síťové vrstvy bychom měli zařadit např. protokol RARP (Reverse ARP), který si můžeme představit jako přesný protipól protokolu ARP: konkrétnímu uzlu, který nezná svou IP adresu, umožňuje zjisti si ji (tak, že opět "do éteru" vznese dotaz, ze kterého je patrná jeho fyzická adresa). Ke stejnému účelu, tedy k získání odpovídající IP adresy na základě adresy fyzické, pak slouží další protokol síťové vrstvy, protokol BOOTP.
Zajímavým protokolem je protokol ICMP (Internet Control Message Protocol). Ten je možné považovat za mechanismus, vytvářející jakýsi "služební kanál". Tím mohou protékat nejrůznější zprávy a hlášení o nestandardních a chybových situacích, na které je třeba reagovat.
Pro potřeby připojování uživatelů k Internetu pak mají doslova klíčový význam dva nové protokoly, SLIP a PPP, které umožňují přenášet IP pakety i po sériových linkách, včetně komutovaných linek veřejné telefonní sítě. Těmto dvěma protokolům je věnován samostatný článek.
Transportní vrstva
Protokoly TCP/IP předpokládají, že nad síťovou vrstvou (Network Layer, IP Layer) se nachází další vrstva, označovaná jako transportní (Transport Layer). Hlavní náplň její práce bychom mohli stručně shrnout následovně: pokud některé aplikaci nevyhovuje charakter služeb, poskytovaných přenosovou částí sítě (přesněji protokolem IP na úrovni síťové vrstvy), je na transportní vrstvě, aby tyto přenosové služby náležitě "obohatila". K tomu se pak přidávají ještě některé další úkoly pro transportní vrstvu - například ten, že transportní vrstva musí umět správně rozdělovat přijímaná data mezi více potenciálních příjemců v rámci téhož uzlu. Zastavme se u tohoto úkolu poněkud podrobněji.
Síťová vrstva a protokol IP mohly ještě vycházet z představy, že přijemci i odesilateli veškerých dat jsou uzly počítačových sítí jako takové, a že tyto uzly nejsou nijak dále dělitelné. Tomu ostatně odpovídala i logika adres, používaných na úrovni síťové vrstvy, neboli IP adres: každá jednotlivá IP adresa identifikovala uzel jako celek. Ve skutečnosti ale na každém uzlu bývá více potenciálních příjemců a odesilatelů dat - více systémových programů, více aplikací - a to dokonce i v případě, kdy nejde ani o víceuživatelský počítač, a dokonce ani o počítač s víceúlohovým operačním systémem. Úkol rozlišovat tyto samostatné příjemce a odesilatele patří až transportní vrstvě.
Transportní vrstva samozřejmě potřebuje vhodný mechanismus, prostřednictvím kterého by dokázala identifikovat různé odesilatele a příjemce dat v rámci daného uzlu. Podstatné je přitom uvědomit si, že těmito příjemci a odesilateli jsou objekty programového charakteru (procesy, úlohy, programy), nacházející se ještě "o patro výše" než vrstva transportní, tedy v aplikační vrstvě. Konkrétní mechanismus, který se pro identifikaci těchto procesů používá v rodině protokolů TCP/IP, je nejlépe si představit jako soustavu přechodových bodů (bran) na rozhraní mezi transportní vrstvou a bezporstředně vyšší aplikační vrstvou. Tyto přechodové body jsou označovány čísly (číselnými identifikátory), a říká se jim porty.
Když pak nějaká aplikace potřebuje odeslat určitá data jiné aplikaci na některém jiném uzlu sítě, předá je k odeslání transportní vrstvě. Přitom k nim musí přidat také informaci o tom, kdo si je má na druhé straně převzít, přesněji přes který port mají být předány. Transportní vrstva odesílajícího uzlu pak příslušná data rozdělí do tak velkých částí, jaké je možné přenášet najednou (jaké je na úrovni síťové vrstvy možné vložit do paketů protokolu IP), a přidá k nim údaje o čísle portu odesilatele i příjemce, a vše odešle (ve skutečnosti: předá k odeslání své bezprostředně nižší vrstvě, tj. vrstvě síťové). Na straně koncového příjemce se pak příslušná data dostanou analogickým postupem až k tamní transportní vrstvě. Ta si z nich "vybalí" údaj o čísle portu na straně příjemce, a podle něj pak vlastní data předá příslušnému příjemci v rámci své aplikační vrstvy.
Zde je dobré si ještě uvědomit, že čísla portů nejsou jednoznačnou identifikací procesů, úloh či programů, běžících na úprovni aplikační vrstvy. To by ostatně bylo i dosti obtížně realizovatelné, neboť tyto programové objekty mohou dynamicky vznikat a zase zanikat. Jednotlivé porty je skutečně třeba chápat jen jako přechodové body, nezávislé na konkrétních procesech. Ty se mohou dynamicky "připojovat" k jednotlivým portům a přijímat vše, co je těmto portům adresováno. Je-li to zařízeno právě takto, pak je například možné, aby existovalo několik tzv. dobře známých portů (well-known ports), s předem pevně danými čísly, kterým mohou být z jiných uzlů adresovány požadavky na poskytnutí určitých konkrétních služeb. Který konkrétní systémový proces, úloha či program je ve skutečnosti přijímá skrz příslušný port, je závislé na momentální situaci, ale pro žadatele (odesilatele) to již není relevantní.
Protokoly TCP a UDP
Vraťme se ale zpět k hlavnímu úkolu transportní vrstvy, kterým je případná změna charakteru služeb, poskytovaných přenosovou částí sítě. Připomeňme si v této souvislosti, že tvůrci protokolů TCP/IP se rozhodli pro takové řešení, v rámci kterého přenosová část sítě poskytuje pouze nespolehlivé přenosové služby, a navíc funguje na tzv. nespojovaném principu. Připomeňme si také, že nespolehlivý způsob přenosu znamená, že přenosová složka nepovažuje za svou povinnost napravovat případné chyby při přenosu, ke kterým dojde (a místo toho očekává, že je napraví někdo jiný). Nespojovaný způsob přenosu pak znamená, že před zahájením přenosu není navazováno spojení mezi odesilatelem a koncovým příjemcem. Motivací přitom byla snaha realizovat přenosovou část sítě co možná nejrychlejší.
Takovýto způsob přenosu, jaký nabízí síťová vrstva a protokol IP, však nemusí vždy vyhovovat. Může, ale nemusí. Některé aplikaci příliš nezáleží na rychlosti, ale naopak by jí silně vadilo, kdyby dostávala jakkoli poškozená či pozměněná data. Příkladem může být elektronická pošta, přenos souborů, vzdálené přihlašování apod. Jiné aplikace naopak preferují maximální možnou rychlost, a kvůli ní se dokáží smířit i s tím, že občas dostanou poněkud poškozená data. Jaké aplikace to mohou být? Nejsnažší je zřejmě představit si některou dnešní multimediální aplikaci, například videokonference, resp. přenos obrazu. Zde je jistě přijatelnější, když čas od času bude některý snímek mít určitý "kaz", způsobený chybou v přenášených datech, ale jednotlivé snímky na sebe budou navazovat konstantní rychlostí. Kdyby ale takováto aplikace trvala na tom, že chce dostávat jen nepoškozená data, a vyžadovala tedy spolehlivý způsob přenosu dat, dostávala by jednotlivé snímky s různými časovými odstupy - protože opravný mechanismus by musel zajišťovat opakovaný přenos některých částí dat. Pro diváka by to pak bylo stejné, jako kdyby mu někdo promítal film, a neustále měnil rychlost posunu filmového pásu.
Autoři protokolů TCP/IP však našli ještě jeden velmi pádný argument pro své uvažování. Uvědomili si totiž, že některé aplikace si stejně budou chtít zajistit spolehlivost přenosu samy (tj. na úrovni aplikační vrstvy), a že by tedy bylo zbytečné jim zajištění spolehlivosti vnucovat znovu i na úrovni transportní vrstvy. Zde je dobré si uvědomit, že přívlastek "spolehlivý" je vždy relativní, a nikoli absolutní. Neexistuje totiž žádný mechanismus, který by dokázal s absolutní spolehlivostí rozpoznat, zda v přenesených datech došlo k chybě či nikoli. Existuje sice celá řada takovýchto detekčních mechanismů, ale každý z nich funguje jen s určitou mírou přesnosti a spolehlivosti. Sice hodně vysokou, ale nikdy ne stoprocentní. Je pak na koncové aplikaci, resp. na koncovém příjemci, aby si rozhodl, zda mu míra poskytované spolehlivosti postačuje, či nikoli. Zcela jinak asi bude vypadat příslušné rozhodnutí například u bankovních aplikací, které zajišťují převody z účtů a účet, a zcela jinak u aplikací, které sbírají údaje o počasí.
Tvůrci protokolů TCP/IP proto dospěli k velmi rozumnému závěru: umožnit každé aplikaci, ať si vybere sama. Tedy ponechat jí volbu mezi tím, zda chce využívat rychlejší, ale zato nespolehlivé přenosové služby (a případnou spolehlivost si zajišťovat sama), nebo zda raději využije pomalejší, ale zato spolehlivý relativně spolehlivý způsb přenosu (a akceptuje míru jeho spolehlivosti). V praxi toto znamenalo, že tvůrci protokolů museli "zabydlet" transportní vrstvu dvěma transportními protokoly: jedním, který bude spíše jednoduchou obálkou nad protokolem IP síťové vrstvy, a k jeho funkčnosti bude přidávat prakticky jen schopnost rozdělovat data podle čísel portů mezi jednotlivé adresáty, a konečně druhým, který již bude výrazněji měnit vlastnosti protokolu IP, a bude zajišťovat spolehlivý přenos. Prvním z těchto dvou protokolů je protokol UDP (User Daragram Protocol), a druhým protokol TCP (Transport Control Protocol).
Na protokolu TCP, který spolu s protokolem IP dal celé rodině porotokolů i jméno, je podstané také to, že kromě zavádění spolehlivosti mění i nespojovaný způsob přenosu (který používá protokol IP) na spojovaný. Neboli že před zahájením každého přenosu navazuje spojení mezi odesilatelem a příjemcem, a pak veškerá data přenáší v rámci takto navázaného spojení.
Jednou pro všechny, nebo pro každého vždy znovu?
Další důležité dilema museli tvůrci protokolů TCP/IP rozřešit bezprostředně nad transportní vrstvou. Ta je totiž poslední vrstvou, která usiluje o to, aby se přenášená data dostala ke svému koncovému přijemci přesně v takovém stavu, v jakém byla odeslána. To ale nemusí být zdaleka vždy žádoucí - může se totiž snadno stát, že dva různé počítače budou jedné a téže posloupnosti bitů a bytů přisuzovat úplně jiný význam. K tomu stačí například to, aby používaly různé způsoby kódování alfanumerických znaků (jeden ASCII, druhý EBCDIC), nebo aby každý z nich používal jiný formát pro znázornění celých čísel i čísel v plovoucí řádové čárce apod. A co například přenos obecnějších datových struktur, ve kterých se vyskytují ukazatele (tzv. pointry). Ty vůbec nemá smysl přenášet, protože "ukazují" někam do paměti odesilatele. Nyní již tedy není problém v tom, jak data správně přenést, ale jak je správně interpretovat.
Samozřejmě existují takové techniky a metody, které právě popsaný problém dokáží řešit. Například tak, že ještě před odesláním zajistí konverzi dat do takového formátu, jakému "rozumí" příjemce. Nebo jinak - přenášená data se před přenosem převedou do jednotného univerzálního "mezitvaru", ke kterému se ještě připojí podrobnější popis významu dat. Důležitá je ovšem jiná otázka: má si tyto mechanismy implementovat až ten, kdo je skutečně potřebuje? S potenciálním nebezpečím, že když je bude potřebovat více různých protokolů vyšších vrstev (přesněji: aplikační vrstvy), budou muset být implementovány vícekrát! Nebo je rozumnější je implementovat jen jednou takovým způsobem, aby mohly sloužit společně všem potenciálním zájemcům - s nebezpečím toho, že je nebude chtít využívat nikdo?
V odpovědi na tuto zajímavou otázku se autoři protokolů TCP/IP opět zásadně rozešli s autory referenčního modelu ISO/OSI. Autoři TCP/IP se přiklonili k zásadě "kdo to chce, ať si to implementuje sám". V důsledku toho pak již nad transportní vrstvou nepotřebovali žádnou další vrstvu, než vrstvu aplikační, ve které jsou soustředěny základní části aplikačních protokolů. Naproti tomu tvůrci referenčního modelu se rozhodli implementovat zmíněné mechanismy bez ohledu na to, zda jsou skutečně potřeba. Pak jim ale vyšlo, že nad transportní vrstvou (koncipovanou obdobně jako u protokolu TCP/IP) potřebují hned dvě další vrstvy - vrstvu relační (session layer) a vrstvu prezentační (presentation layer). A to je další výrazný rozdíl mezi oběma síťovými koncepcemi.
Kam patří aplikace?
Jistě není třeba zdůrazňovat, že uživatele zajímají především aplikace, a méně již "to, co je vespod". Bylo by ovšem chybou domnívat se, že aplikace je to, co je provozováno na úrovni aplikační vrstvy, nebo obráceně že "aplikační vrstvu je to, kde jsou provozovány aplikace". Problém je totiž v tom, že když něco spadá do určité vrstvy síťového modelu, mělo by to být standardizováno - neboli pokryto standardy, které přesně říkají, jak má co pracovat, fungovat atd. A sem by měla patřit například grafická uživatelská rozhraní či konkrétní "obrazovky" jednotlivých aplikací? Pokud ano, musely by se všechny aplikace na své uživatele "tvářit" stejně, mít naprosto stejné vlastnosti, funkce, i svůj celkový "image".
Standardizovat tímto způsobem všechny aplikace není únosné (již jen kvůli objemu práce, který by to vyžadovala), a dokonce ani žádoucí. Na druhé straně je ale určitá míra standardizace nezbytná - mají-li si vzájemně rozumět například dvě aplikace pro elektronickou poštu, musí se shodnout na přesném formátu zpráv, které si budou předávat, na konkrétním mechanismu přenosu těchto zpráv atd. Na čem se naopak shodnout nemusí, je uživatelské rozhraní, které budou svým uživatelům vytvářet - jedna aplikace může nabízet jen velmi strohé, znakově orientované uživatelské rozhraní v prostředí MS DOSu, zatímco druhá může poskytovat plně komfortní grafické rozhraní v prostředí MS Windows, se všemi obvyklými "okenními vymoženostmi".
Výsledným efektem je pak skutečnost, že do aplikační vrstvy se zařazují pouze části aplikací - ty, které je žádoucí standardizovat - zatímco zbývající části aplikací (které naopak nemá smysl svazovat případnou standardizací) se vysouvají nad aplikační vrstvu. I díky tomu je pak možné, aby si v prostředí počítačové sítě navzájem rozuměly a dokázaly spolupracovat aplikace, pocházející od různých výrobců, provozované na různých typech počítačů, v prostředí různých operačních systémů apod. Snad nejmarkantnější je to právě v citovaném případě elektronické pošty, ale totéž platí v zásadě pro jakýkoli druh aplikace.
Inventura aplikací
Každý pokus o úplný výčet všech aplikací, které je možné provozovat v prostředí počítačových sítí, je předem odsouzen k nezdaru - z toho důvodu, že takovýchto aplikací je velmi mnoho, jsou velmi různorodé, a neustále vznikají nové a nové. V podstatě kdokoli může přijít, vymyslet a naimplementovat zcela nový druh aplikace. Pokud se ukáže, že je potřebná, užitečná či z jiného důvodu úspěšná, dojde časem k tomu, že vznikne určitý konsensus o tom, jak má fungovat - přesněji jak má fungovat její relevantní část, podstatná pro celkový efekt aplikace a pro možnost vzájemné spolupráce mezi různými implementacemi téže aplikace. Tento konsensus pak dostane formu standardu, ať již psaného a formálně vymáhaného standardu de jure, nebo spíše neformálního a především dobrovolně dodržovaného standardu de facto.
Existuje samozřejmě určitá množina aplikací, které již mají svou standardizaci úspěšně za sebou. Některými z nich se budeme zabývat podrobněji v dalších tématech týdne o Internetu, zatímco pro jiné nám vůbec nezbyde prostor. Na tomto místě si proto udělejme jen malou inventuru základních aplikací, které jsou nejčastěji provozovány v prostředí TCP/IP sítí obecně a v Internetu konkrétně, a vyjmenujme si protokoly a standardy, které byly pro tyto aplikace vyvinuty:
- elektronická pošta (electronic mail): pro elektronickou poštu existují dva relevantní standardy: první z nich se obvykle označuje jako RFC822 (podle dokumentu Request For Comment s pořadovým číslem 822), a definuje základní formát zpráv, přenášených elektronickou poštou, včetně formátu používaných elektronických adres. Druhý standard definuje protokol, používaný pro vlastní přenos jednotlivých zpráv. Tímto protokolem je protokol SMTP (Simple Mail Transfer Protocol), podle kterého je také el. pošta v rámci TCP/IP sítí neformálně označována - jako SMTP pošta, SMTP-kompatibilní pošta apod. Určitou nevýhodou těchto dvou standardů je skutečnost, že jsou šity na míru potřebě přenášet textové zprávy, nejspíše jen v angličtině - nepamatují ani na možnost přenosu znaků v náropdních abecedách, ani možnost přenosu binárních souborů elektronickou poštou (napříkladve formě přílohy). Pro tento účel byl v nedávné době vyvinut standard MIME (Multipurpose Internet Mail Extension), který již umožňuje přenášet elektrnickou poštou jak texty v nejrůznějších národních abecedách, tak i všelijaké druhy příloh - například zvukové či obrazové záznamy, binární datové soubory apod. Pro potřeby přenosu elektronické pošty mezi poštovními servery a samostatnými uzlovými počítači byly vytvořeny další protokoly, mj. POP2 a POP3, IMAP2 a IMAP3 a DSMP.
- síťové news (network news): pro přenos a distribuci jednotlivých příspěvků síťových news je možné použít mnoho různých přenosových mechanismů,. V prostředí Internetu je doporučeným mechanismem protokol NNTP (Network News Transfer Protocol).
- přenos souborů (file transfer): pro přenos souborů se v prostředí TCP/IP sítí používá protokol FTP (File Transfer Protocol). Jde přitom o tzv. netransparentní přenos, při kterém musí uživatel znát umístění a jméno souboru, se kterým chce pracovat.
- sdílení souborů (file sharing): pro plně transparentní sdílení souborů se v prostředí TCP/IP sítí používá protokol NFS, původně vyvinutý firmou Sun Microsystems jako její proprietární řešení. Posléze však byl tento protokol standardizován (formou dokumentu RFC).
- vzdálené přihlašování (remote login): pro potřeby vzdáleného přihlašování v prostředí TCP/IP sítí je nejčastěji využíván protokol Telnet.
- správa sítě (network management): pro tento účel je využíván protokol SNMP (Simple Networek Management Protocol,), který v současné době existuje již i ve verzi SNMP-2.