


Síťová vrstva - směrování
Neexistuje-li v počítačové síti přímé spojení mezi odesilatelem dat a jejich koncovým příjemcem, je úkolem síťové vrstvy nalézt mezi nimi alespoň takovou cestu, která vede přes některé jiné uzly sítě. Z předchozích dílů našeho seriálu již víme, že v případě tzv. virtuálních okruhů se takováto cesta hledá jen jednou, a to na začátku komunikace obou koncových účastníků (v rámci navazování spojení resp. zřizování virtuálního okruhu), zatímco u tzv. datagramové služby se vhodná cesta hledá pro každý jednotlivý paket (resp. datagram) pokaždé znovu. Víme již také, že problematika hledání cest v síti se obecně označuje jako směrování (routing). Co však ještě nevíme, je jak se taková cesta vlastně hledá.Pro nalezení vhodné cesty od odesilatele až ke koncovému příjemci existuje celá řada algoritmů směrování (routing algorithms), které jsou založeny na různých myšlenkách a principech, a vyžadují různé stupně znalosti sítě, její topologie a dalších parametrů statického i dynamického charakteru. Všechny algoritmy směrování by ovšem měly být korektní, tedy dávat jen takové výsledky, které jsou správné a použitelné, měly by být co možná nejjednodušší, nejsnáze implementovatelné, a jejich režie by měla být minimální. Současně s tím by ale algoritmy směrování měly být i tzv. robustní, tedy schopné vyrovnat se s nepředvídanými výpadky, poruchami či jinými nestandardními situacemi. Měly by také usilovat o optimální využití celé sítě a její přenosové kapacity, a přitom nikoho nediskriminovat - tedy někomu hledat "lepší" cesty, a někomu "horší".
Výsledným efektem aplikace algoritmů směrování by mělo být to, aby síťová vrstva v každém z uzlů sítě věděla, kudy poslat dále takový paket, který není určen přímo jejímu uzlu. Konkrétní pokyny pro směrování paketů resp. datagramů, které vznikají na základě aplikace algoritmů směrování, se pak v jednotlivých uzlech uchovávají ve formě tzv. směrovacích tabulek (routing tables).
Adaptivní a neadaptivní směrování
V prvním přiblížení si můžeme rozdělit algoritmy směrování na dvě velké skupiny. Do první z nich budou patřit takové, které se snaží průběžně reagovat na skutečný stav sítě, a brát jej do úvahy při svém hledání nejvhodnější cesty. Dokáží se tedy přizpůsobit okamžitému stavu sítě, a proto se obecně označují jako adaptivní algoritmy (adaptive algorithms). Naproti tomu neadaptivní algoritmy (nonadaptive algorithms) nevyužívají žádné informace dynamického charakteru - např. údaje o okamžitém zatížení jednotlivých přenosových cest, výpadcích, délkách čekacích front v jednotlivých uzlech apod. Svá rozhodnutí staví pouze na informacích statického charakteru, které jsou předem známy. Díky tomu lze neadaptivní algoritmy použít k nalezení všech potřebných cest ještě před uvedením sítě do provozu, a potřebné informace pak jednorázově zanést do směrovacích tabulek jednotlivých uzlů sítě. Kvůli statickému charakteru výchozích údajů se použití neadaptivních algoritmů někdy označuje také jako tzv. statické směrování (static routing). Je vhodné tam, kde topologie sítě je skutečně neměnná, kde prakticky nedochází k výpadkům a kde se příliš nemění ani intenzita provozu resp. zátěž sítě.
Centralizované směrování
Adaptivní algoritmus může být koncipován tak, že veškeré informace o aktuálním stavu celé sítě se průběžně shromažďují v jediném centrálním bodě, tzv. směrovacím centru (RCC, Routing Control Center), které pak na jejich základě samo přijímá všechna potřebná rozhodnutí, a ostatním uzlům je oznamuje. Pak jde o tzv. centralizované směrování (centralized routing). Jeho výhodou je možnost optimálního rozhodování na základě znalosti skutečného stavu celé sítě. Problém je ovšem v tom, že má-li být centralizované směrování opravdu adaptivní, tedy má-li průběžně reagovat na aktuální stav sítě, musí být vyhledávání nejvhodnějších cest prováděno dostatečně často. Vlastní hledání cest je samo o sobě operací značně náročnou na výpočetní kapacitu, a má-li se často opakovat, dokáže plně zaměstnat i velmi výkonný počítač. Jsou zde však ještě i další problémy - co například dělat v případě výpadku směrovacího centra? Nezanedbatelná není ani zátěž přenosových cest, kterou představuje neustálý přísun aktuálních informací o stavu sítě do směrovacího centra, stejně tak jako zpětná distribuce výsledků.
Izolované směrování
Alternativou k centralizovanému směrování je tzv. izolované směrování (isolated routing), založené na myšlence, že rozhodovat o nejvhodnější cestě si bude každý uzel sám za sebe, a to na základě takových informací, které dokáže získat sám, bez spolupráce s ostatními uzly. Jednou z možností realizace je algoritmus, nazvaný příznačně algoritmem horké brambory (hot potato algorithm). Jak jeho název dává tušit, snaží se uzel zbavit každého paketu resp. datagramu co možná nejrychleji. Sleduje proto počet paketů, které čekají ve frontě na odeslání jednotlivými směry, a nový paket zařadí do té fronty, která je momentálně nejkratší. Uzel se tedy nerozhoduje podle adresy, ani nehledá nejkratší cestu pro přenos paketu, pouze se jej snaží co nejrychleji zbavit ve víře, že po jisté době přeci jen dojde ke svému cíli. V praxi se ovšem algoritmus horké brambory spíše kombinuje s jinými algoritmy resp. metodami - nejčastěji je používán jako jejich doplněk, který se uplatní až v okamžiku, kdy počet paketů v některé frontě překročí určitou únosnou mez.
Zpětné učení
Jiným příkladem izolovaného směrování je tzv. metoda zpětného učení (backward learning). Předpokládá, že každý uzel si do svých směrovacích tabulek průběžně poznamenává, ze kterého směru dostává pakety, pocházející od jiných uzlů. Tím se postupně "učí", ve kterém směru se tyto uzly nalézají. Když pak sám potřebuje odeslat nějaký paket jinému uzlu, vyšle jej tím směrem, ze kterého dříve přijal paket, pocházející od téhož uzlu.
Problémem je ovšem vrozený optimismus metody zpětného učení. Dojde-li k výpadku určité přenosové cesty, kterou se jednotlivé uzly již "naučily", vůbec ji nezaznamenají. Prakticky jediným možným řešením je pak pravidelné "zapomínání".
Záplavové směrování
Extrémní formou izolovaného směrování je tzv. záplavové směrování (flooding). Předpokládá, že přijatý paket je znovu odeslán všemi směry kromě toho, odkud sám přišel.
Zřejmou výhodou je maximální robustnost, díky které se záplavové směrování dokáže vyrovnat prakticky s jakýmkoli výpadkem. Zaručuje také, že každý paket je vždy doručen tou nejkratší možnou cestou. Nevýhodou je ale vznik velkého množství duplicitních paketů, které výrazně zvyšují zátěž existujících přenosových cest, a které je třeba následně rušit.
V praxi se proto používá spíše tzv. selektivní záplavové směrování (selective flooding), při kterém není každý paket znovu vysílán všemi směry, ale pouze těmi, které jsou alespoň přibližně orientovány ke konečnému příjemci paketu.
Distribuované směrování
Metody izolovaného směrování staví na předpokladu, že jednotlivé uzly nebudou zatěžovat přenosové cesty vzájemnou výměnou informací o stavu sítě. To je ale někdy zbytečně přísným omezením.
Pokud jej odstraníme, dostaneme tzv. distribuované směrování (distributed routing). To předpokládá, že jednotlivé uzly si pravidelně vyměňují informace o stavu sítě, a podle nich si pak samy volí příslušné cesty.
Jakmile umožníme výměnu stavových informací mezi jednotlivými uzly sítě, můžeme vcelku efektivně implementovat distribuovanou verzi algoritmu hledání nejkratších cest v síti, který bychom zřejmě používali v případě centralizovaného směrování a jediného směrovacího centra. Naznačme si nyní myšlenku tohoto distribuovaného algoritmu.
Nejprve si však musíme ujasnit, co vlastně bude pro nás měřítkem "délky" nějaké cesty. Může to být například počet meziuzlů, kterými cesta prochází. Tím však dáváme každému existujícímu spoji mezi dvěma uzly stejnou jednotkovou váhu resp. délku. Realističtější je přiřadit vhodné ohodnocení (délku) každému přímému spoji mezi dvěma uzly, a délku výsledné cesty pak chápat jako součet délek jejích jednotlivých částí. Délka spoje přitom může odrážet jeho přenosovou rychlost, cenu za jednotku přenesených dat, zpoždění při přenosu, délku výstupních front apod.
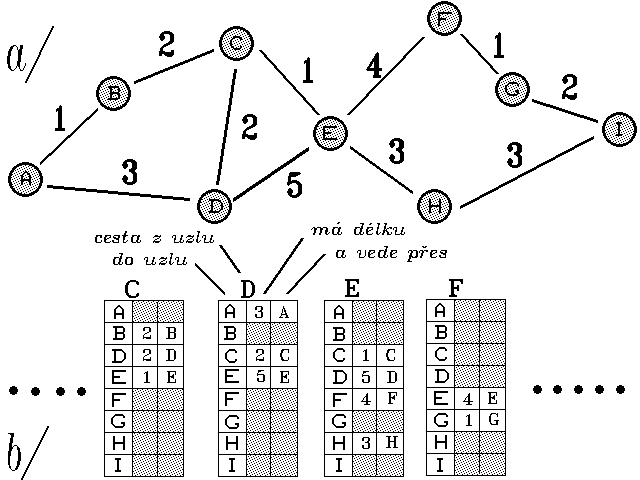
Představme si nyní síť dle obrázku 34.1. a/, včetně "délek" jednotlivých přímých spojů. Každý uzel předem zná svou "vzdálenost" od všech svých sousedů, a tak si ji ve své směrovací tabulce vyznačí. Svou vzdálenost (délku nejkratší cesty) od ostatních uzlů však ještě nezná, a tak ji zatím považuje za nekonečnou (na obrázku naznačeno vyšrafováním). Počáteční stav tabulek ukazuje obrázek 34.1. b/.
Vlastní algoritmus distribuovaného výpočtu pak probíhá v opakujících se krocích. V každém z nich se každý uzel dotáže svých bezprostředních sousedů, jaké jsou jejich vzdálenosti od ostatních uzlů, a podle toho si pak odvozuje i své vlastní vzdálenosti od těchto uzlů.
Uvažme příklad uzlu E. Ten se v prvním kroku od svého souseda C dozví, že jeho vzdálenost od uzlu B je 2. K ní si uzel E připočte svou vzdálenost od uzlu C, tj. 1, a do své směrovací tabulky si poznačí, že cesta do uzlu B vede přes uzel C a má délku 3. Zatím však nezná všechny možné cesty do uzlu B, a tak neví, zda je to cesta nejkratší. Proto se bude v dalších krocích znovu ptát všech svých sousedů, zde přes ně nevede cesta ještě kratší.
Obecně si každý uzel vždy volí minimum z toho, co "již umí" on sám (tj. z cesty, kterou již má poznačenu ve své směrovací tabulce), a co "umí" jeho sousedé (samozřejmě s uvážením své vzdáleností od těchto sousedů). Příkladem může být opět uzel E, který si již na počátku do své směrovací tabulky zanese, že jeho vzdálenost od uzlu D je 5 (což je délka jejich přímého spojení, viz obr. 34.1 a/). Již v prvním kroku však od svého souseda C zjistí, že jeho vzdálenost od uzlu D je jen 2. Když si k tomu připočítá svou vzdálenost od uzlu C (tj. 1), vyjde mu, že cesta do uzlu D, vedená přes uzel C, je kratší. Tuto skutečnost si pak poznačí do své směrovací tabulky (viz obrázek 43.1 b/ a c/, tabulka uzlu E, položka D).
 | 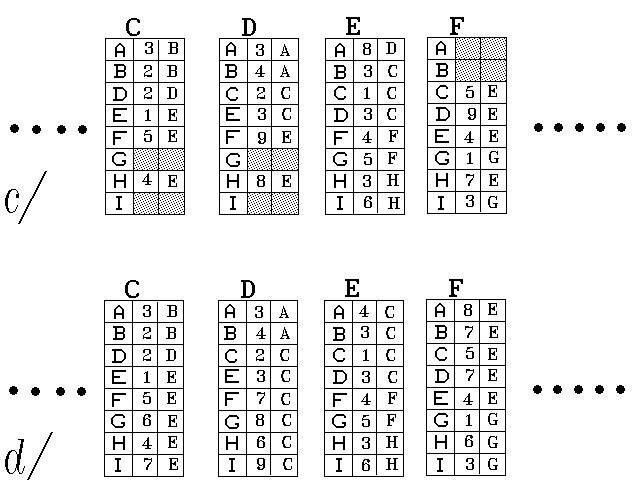 |
Právě naznačený algoritmus distribuovaného směrování byl používán v síti ARPA (základu dnešní sítě Internet), a jednotlivé kroky algoritmu zde probíhaly s intervalem 640 milisekund. Ukázalo se však, že režie je přeci jen příliš vysoká - že vzájemné předávání informací mezi sousedními uzly (které vlastně představuje předávání celých směrovacích tabulek) neúnosně zatěžovalo dostupné přenosové cesty na úkor "užitečných" dat. Proto byl uvedený algoritmus distribuovaného směrování v síti ARPA nahrazen jiným - o něm si ale budeme povídat později.